
I have a lot of excel spreadsheets that all have the same attribute schema. However, there are a varying number of header lines that precede the data in each.
In FeatureReaders & Readers, we define the start point for data by line number. Given the consistency of the attribute schema and the inconsistency of the header spiel, I’m trying to think of a way to only read in the ssheets from the start of the data/attribute names, i.e. dynamically, defined by the first attribute name rather than the line number (I guess).
Any ideas?

Solved
Dealing with Excel where attribute schema is consistent but number of 'read me' header rows is not

") +8
+8- Supporter
Best answer by geomancer
You could do something like this:
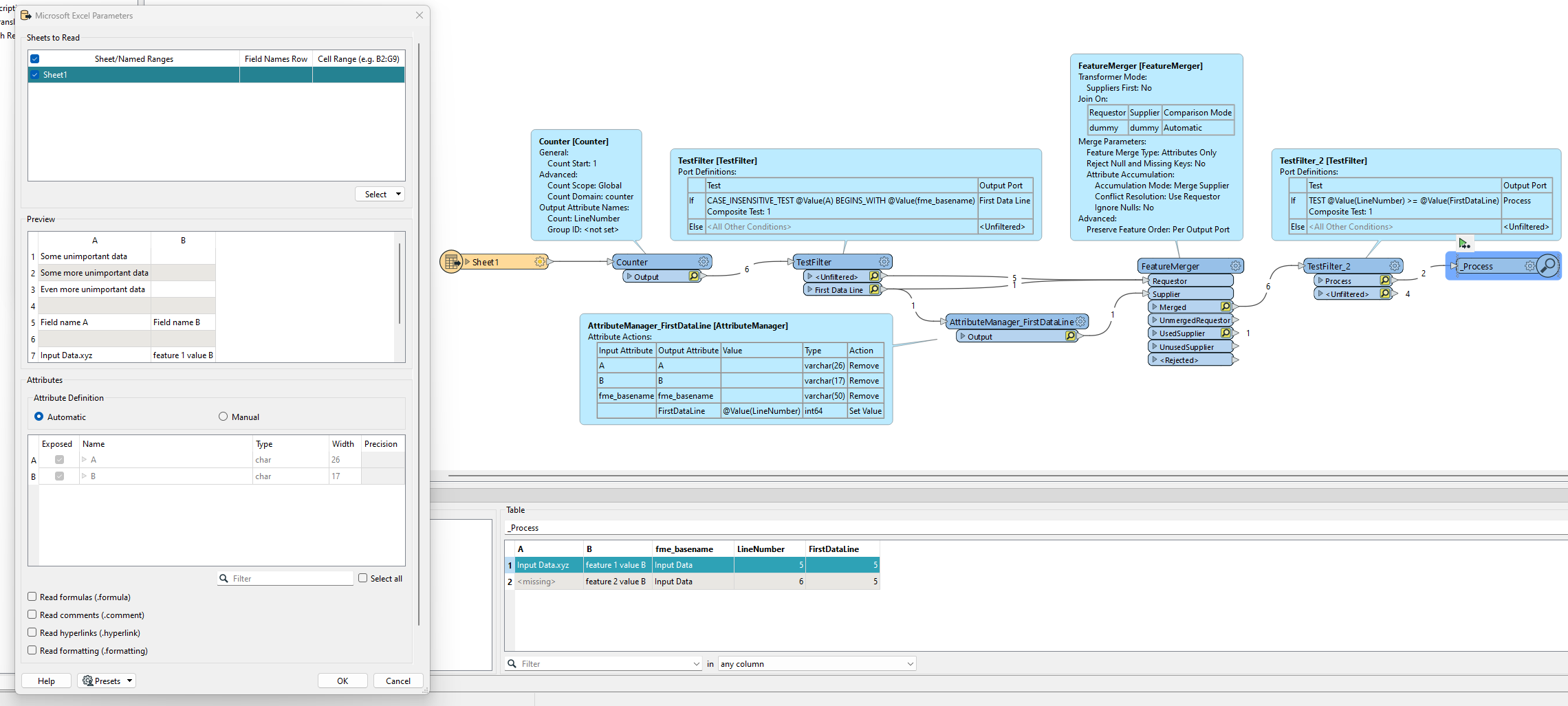
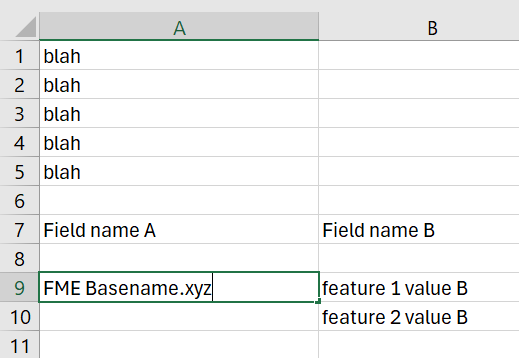
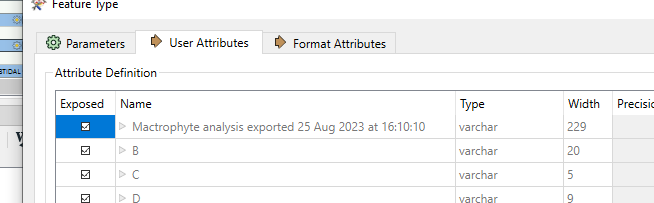
- When reading the Excel file, under Parameters set Field Names Row and Cell Range to empty. FME will name your columns A, B, etc. Also expose fme_basename
- Add a line number using a Counter
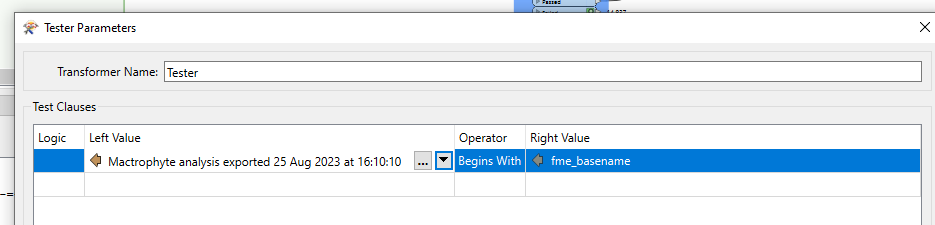
- Filter out the feature where column A starts with your fme_basename
- Add an attribute to this feature, set it to the line number, remove the other attributes
- Merge this feaure to all existing features
- Select only the features where the line number is greater then or equal to the line number from step 4










Reply
Rich Text Editor, editor1
Editor toolbars
Press ALT 0 for help
Helpful Members This Week














Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.