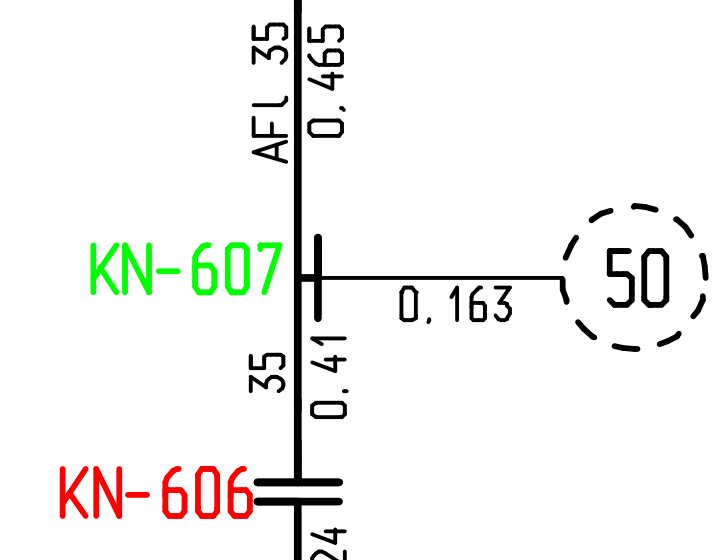
Any ideas how would FME power be able to convert a 'decapitated' CAD file back to text?
I have a PDF file which used to be a CAD drawing (not sure if Autodesk or Bentley) and it contains only a 'dropped/exploded' line segment geometry. I have managed to read it into FME as line geometries, rotate the page so that it's 'level' and use LineCombiner to join segments back to 'character shapes'.
Now I have geometries as shown below (some are perfect characters, some are in 2-3 parts, like 'd or b') and have no idea how to turn it back into text. I tried exporting it to DGN but Microstation doesn't seem to have a function like that either (i.e. once you drop/explode a text to lines, there's only 'Undo' to help, no function to 'characterise' it again, that I found).
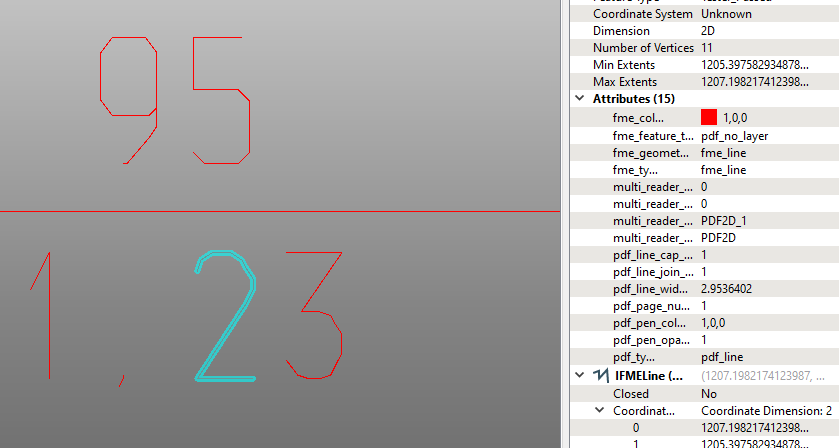
Also tried rasterising it with ImageRasterizer and then calling a Tesseract to attempt OCR, but it notoriously returns 'No text found' regardless of resolution, colour, pixel size, background colour or language.
So any further ideas how to resurrect this 'almost there' file?