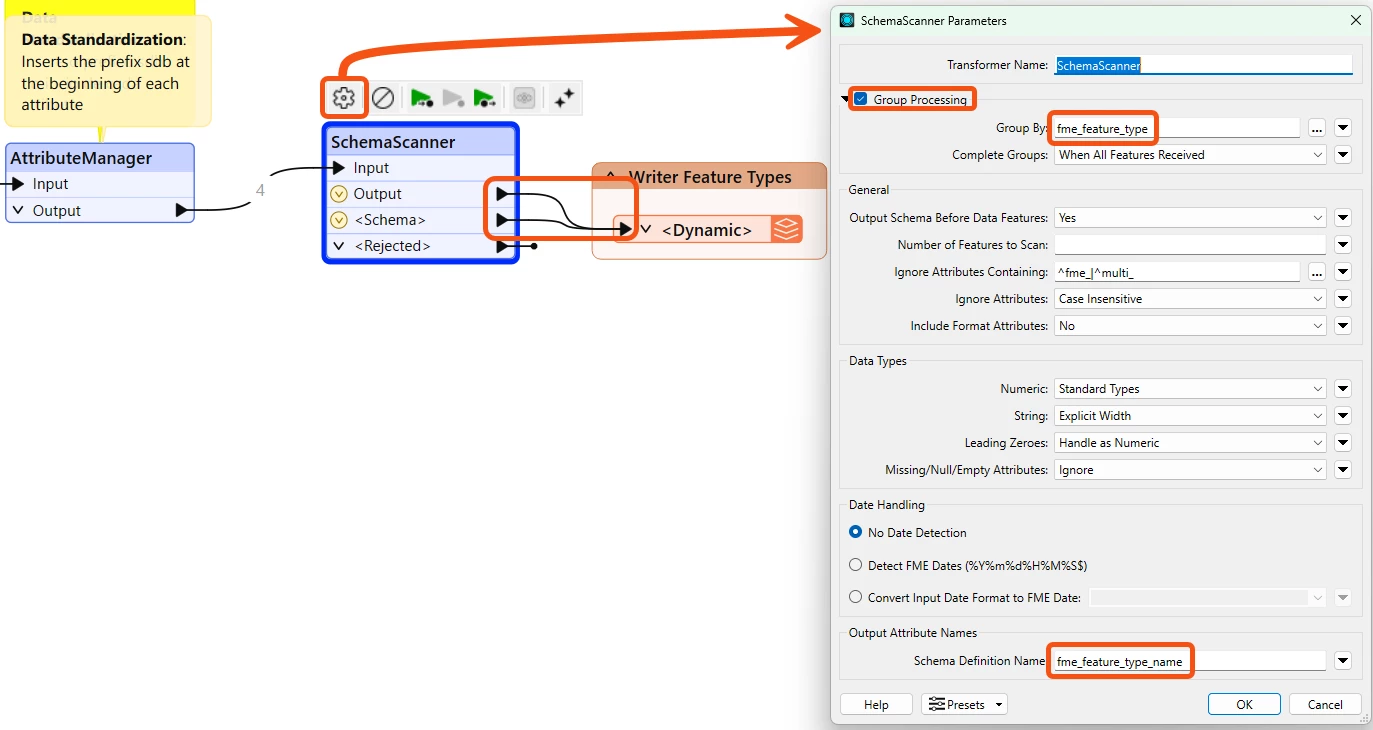
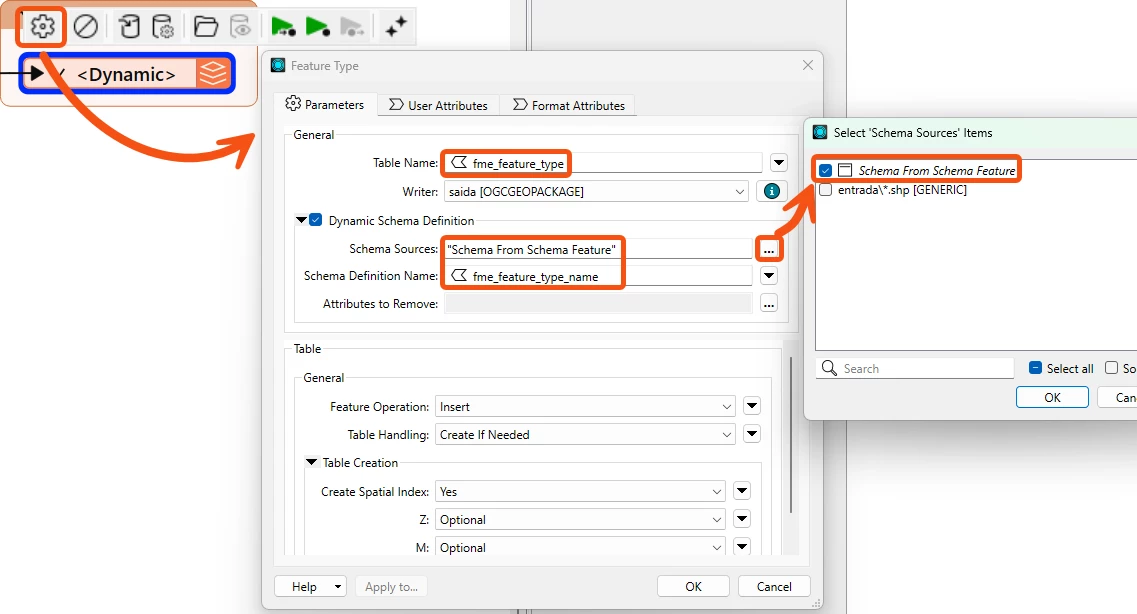
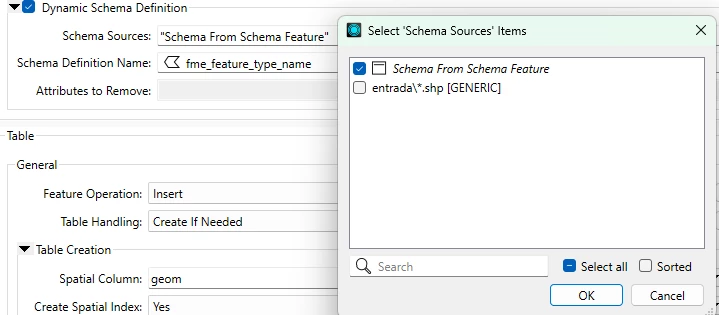
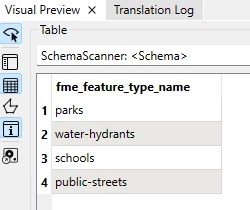
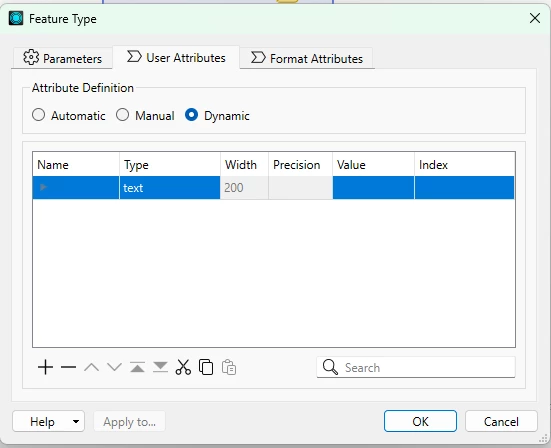
I am using a generic/dynamic schema in FME Workbench, and I have a workspace that processes multiple different datasets through the same workflow.
At the end of the process, each dataset is written separately to the writer. However, I noticed that the outputs end up inheriting attributes from other datasets, which remain in the schema but with empty values, even though those attributes do not exist in the original source.
I would like to understand:
-
Why does FME keep attributes from other datasets when using a generic schema?
-
What is the best practice to prevent schemas from being mixed ?
Has anyone encountered this scenario or could suggest the correct approach to keep independent schemas for each dataset?