


Hi FME'ers,
Not so much a single Question-of-the-Week, so much as a common theme related to handling a schema that is unknown or needs to be constructed dynamically.
Question of the WeekQ) How to set the attribute name to published/private parameter value in FME 2019.1 ? Is it possible to do ?
Asked here. Similar issues asked here (compare two schemas for duplicate fields) and here (dynamically create columns from attribute values)
A) All of these questions deal with the concept of schema. Mostly we start out with a fixed schema: we know the source data structure and we know the required destination structure.
But sometimes we don't know what the incoming schema will be, which leads to problems. We can't predefine handling it in the workspace, and we don't know how to define the destination structure.
So let's take a look at schemas and see how to solve some of these issues.
Where Does the Output Schema Come From?First, here's the theory part. The schema for a writer comes from one of four places:
- A manual (fixed) definition in the workspace
- An automatic (but still fixed) definition in the workspace
- A separate dataset
- An automatic (dynamic) definition in the workspace.
A manual (fixed) definition is easy enough. You go to the writer feature types and you manually enter the attribute structure you want.
An automatic definition is also easy. You click the feature type and set the definition to Automatic. Now whatever changes you make in the workspace get reflected automatically in the output schema:
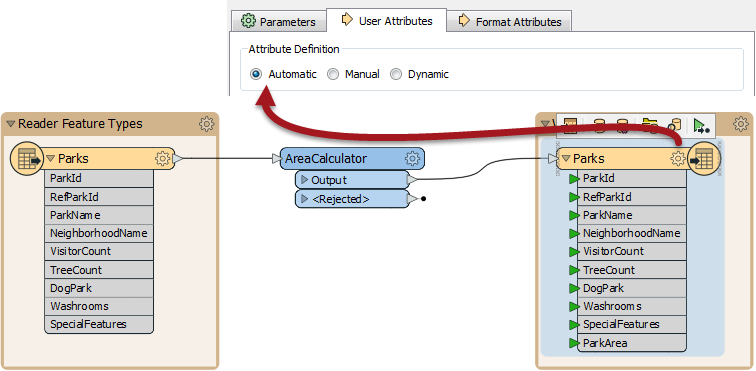
So, above, ParkArea is added to the output schema automatically when the AreaCalculator creates it. This is really still a fixed schema, just made easier to create in the workspace; like, FME adds ParkArea so you don't have to do it manually.
A dataset definition is fairly straightforward too. It's the simplest of the dynamic methods. You simply point to a dataset and in effect tell FME to make the output attribute structure the same. It's great because it doesn't even have to be the same format. Like, "I'm writing this data to an Excel spreadsheet and I'd like it to have the same structure as this table in Postgres please":
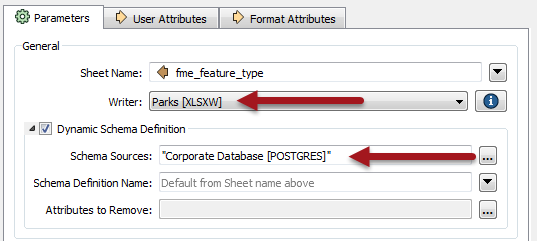
It's dynamic because if the Postgres table changed, the next time you run the workspace, the new table schema is used. The only difficulty is that you must make sure the source data maps to the new schema, but you can do that outside of FME using lookup tables and a SchemaMapper transformer.
The final option is to create the schema dynamically inside the workspace. We call this schema from features. You create the schema using attributes, like so:
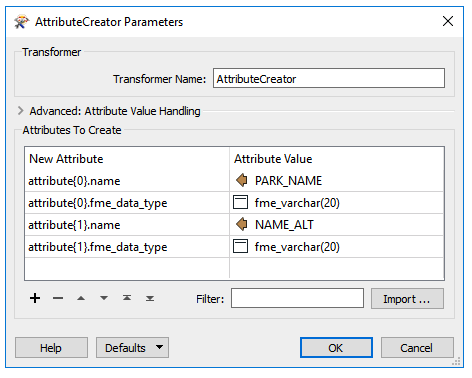
Of course, you can get the attribute names and types from anywhere: manually defined (like above) or (as we'll see below) read from a text file, or literally anywhere.
Overall, it really helps to think of "schema" as being its own separate entity. But how does this help with the users’ questions?
Dealing with Unknown InputSo the main question is from a user who wants to create a new attribute whose name is entered as a published parameter at run time. That's quite simple to do. You just use an AttributeCreator where the name of the attribute to create is the value of the parameter:
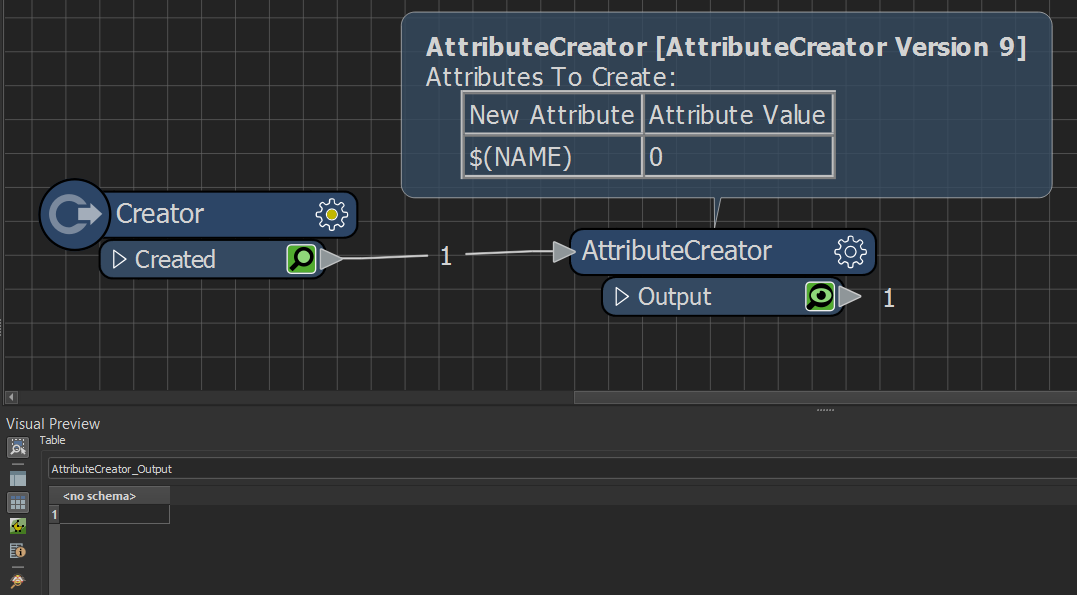
The confusing part is what do you do next? Why can't you see the attribute exposed in the workspace or in the writer schema?
Well, the reason FME can't expose the attribute is simple: it doesn't know what you are going to enter into the published parameter. The value you enter is a future event and FME can't see into the future!
But it doesn't really matter that you can't see it. Firstly, inside the workspace, what you can do is continue to use references to that parameter. Like in a Tester transformer you could test for:
= 1...which I think works fine.
Secondly, the attribute is there, whether you can see it or not. All you need to do is make sure it gets added to the output schema.
For example, if you are defining the output schema dynamically, by pointing to a dataset (say a Postgres table) then you just need to make sure that the Postgres table contains an attribute of the same name as the parameter input.
Or, to be even more dynamic, you create the schema inside the workspace using attributes, because you can set the name to actually be the value of the parameter:
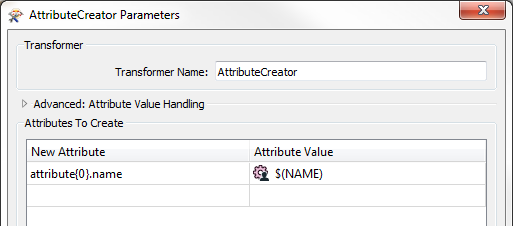
Now it's on the schema the attribute will be written to the output. It's just a case of considering "what is schema?" and "how do I create my schema?"
Knowing that, what about the other two questions...
Other Schema QuestionsLet's take the question about creating attributes dynamically from incoming data. That turns out to be very simple, due to an FME Hub transformer I wasn't aware of called the AttributeTransposer.
The issue - of course - is how to write that data. You can't manually define the schema, because you don't know the incoming attributes. So - as @virtualcitymatt points out - you make a dynamic translation. There's even another FME Hub transformer - the SchemaSetter - that will set up the schema attributes automatically for you!
The final question I tagged, is more about how to tell what attribute schema incoming features have. Remember I said to think of schema as a separate entity to data? So instead of using a reader to read the data, you use a reader to read the schema.
As @david_r responds, there is a format called Schema (Any Format) that will read the schema of a dataset:
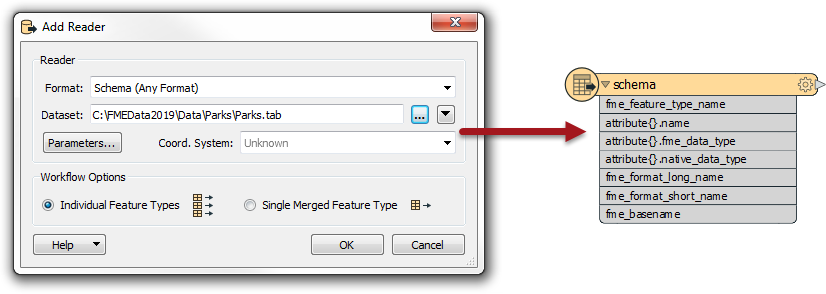
It's like a generic format reader, but for schema instead of data. Notice that the incoming schema is stored in the same format of attribute as you would create to write a schema dynamically. So you could read a schema, transform it in whatever way you wanted inside the workspace, then use that amended schema as the structure to use for writing data.
OverviewThere are a couple of things I'd like you to take from this post.
Remember that FME can't expose an attribute in a workspace if you don't know what it is. But that attribute still exists, even if it's hidden from view.
Similarly, FME can't define a schema in a workspace if you don't know what it's going to be. But you can tell FME to wait until run time to make that decision, by using a dynamic workflow.
Combine the two and you have the knowledge to make very flexible and powerful workspaces indeed.
For a full run-down on dynamic workflows I recommend the dynamic workflow tutorial on this site. It is very useful, trust me!
Other Notable QuestionsA few other questions I noticed this week...
- How do you map attributes from one value to another, when the mapping is not a simple matter of equivalency (like the AttributeValueMapper)? @markatsafe (as opposed to me, @mark2atsafe) suggests Conditional Attribute Values. He also suggests you upvote this idea, to create a new transformer. A "TestMapper" transformer, if you will. I agree it would be very useful, to help newer users without using conditional values.
- Can you reference images from inside a PDF file? As @jovitaatsafe explains, we don't support that. In fact PDF only supports it for JPEG files, so it wouldn't work for this user with PNG files anyway. There are two workarounds though: either embed the png files directly into the PDF or, if they really don't want to embed all those images, use the PDFStyler to create a link to the file. Also thanks to our developer Jake for coming up with this nice info.
- How to denormalize a spreadsheet. Don't worry @iainfletcher - we're very nice to new users here! If the solution by @ebygomm helps then mark her answer as accepted please. Otherwise, let us know and we'll be glad to help out some more.