Dear community,
I don't find a solution to my problem and hope someone can help.
To automatically create XML documents for a metadata catalog, I created a generic FME workspace. An SQL Creator serves as an initiator to a FeatureReader and all features and feature classes are received through the <Generic> Port of the FeatureReader.
Because I tend to create a document for each feature class (POSTGIS table) rather than for an individual feature, I use an Aggregator to only have one feature per feature class. Important here seems to be that I use the Group By setting which groups all features by feature class (attribute fme_feature_type).
After having gathered all necessary information for each deature class (like bounding box and description/title) with various transformers, the processing chain comes to the XML templater which creates the XML file document.
The problem is that I have no idea how to deal with the keywords that are saved in a list attribute (array). I have a root template for the main document and sub template for the keywords.
Currently I use this code to insert the keywords into the root document:
<gmd:MD_Keywords>
{fme:process-features("SUB_KEYWORDS")}
<gmd:type>
<gmd:MD_KeywordTypeCode codeListValue="theme"
codeList="http://standards.iso.org/ittf/PubliclyAvailableStandards/ISO_19139_Schemas/resources/codelist/ML_gmxCodelists.xml#MD_KeywordTypeCode"/>
</gmd:type>
</gmd:MD_Keywords>
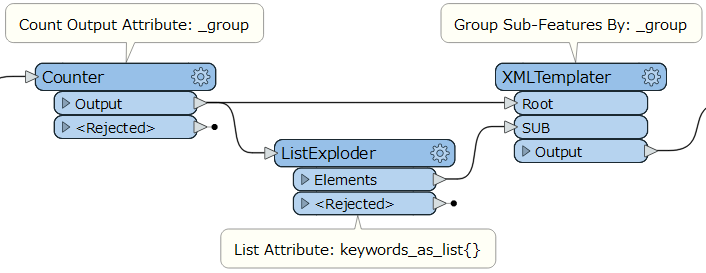
The process-features function expects separate features as input. To convert the list contents to separate features I use the ListExploder
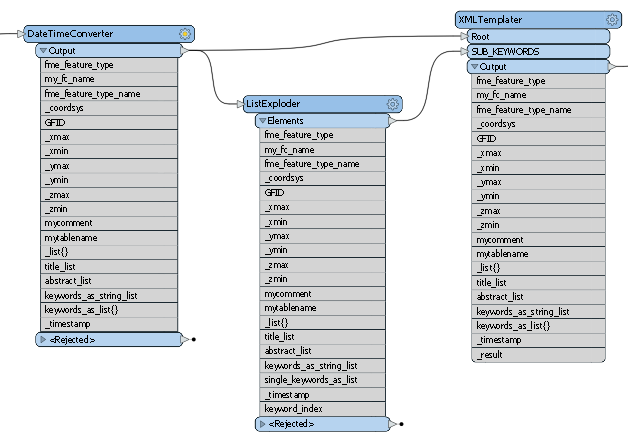
This doesn't work because by forking the stream, I somehow loose the grouping for the ListExploder. For some reason, the resulting XML documents list all keywords that have been collected from all individual feature classes or described differently: the keywords from different feature classes have been combined and inserted to each XML document while all other attributes are kept separately and written to the specific XML document for one feature class.
my questions:
- why are the features that enter the ListExploder not grouped or as it is written in the documentation:
"Each group of features that have the same values for the Group By attributes will be processed independently of other groups." It seems that the ListExploder waits for all features from the separate feature classes to arrive and releases the accumulated keywords for every group that enters the transformer - Is there a way to get out of this and use process template instead of process-features which is more appropriate because the keywords belong to the same feature that enters the XMLTemplater? Can I enter code in the sub template that iterates over all elements of the keyword list and have it generate a corresponding keyword fragment like illustrated in this pseudo code:
String xmlFragment = ""
for each $keyword in fme:get-attribute("keywords_as_list")
{
xmlFragment+="<gmd:keyword xmlns:gmd="http://www.isotc211.org/2005/gmd"><gco:CharacterString xmlns:gco="http://www.isotc211.org/2005/gco">{$keyword}</gco:CharacterString></gmd:keyword>";}
What is the best approach here to retain the groups and keep the keywords separated from each other?
Thank you very much for your comments,
Michael