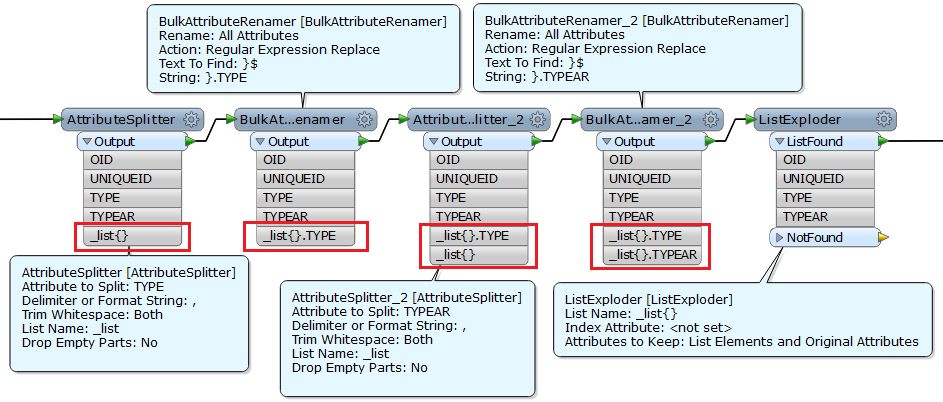
I have some data in the following structure (with some other columns not really of interest) which needs to be represented as features with only one input into each column;
Each feature represents a polygon; there needs to be just one code under 'TYPE' and one under 'TYPEAR'. Where there are more then one code in a column, i need those to become new features (taking the UniqueID of where it came from). The corresponding positions of the code in TYPE and TYPEAR are correct (ie 1st letter goes with 1st decimal value etc)
n represents the fact that I have many files like this with many 1000s of features in each one.
So, i used AttributeSplitter for 'TYPE' and also for 'TYPEAR', splitting by the comma, creating a list for each attribute. I then used ListExploder for _listTYPE{} and _listTYPEAR{} and created a new feature based on the lists.
However, exploding by one list is all fine - eg Exploding _listTYPE{} will create a feature for each letter code within a uniqueID - but as the TYPEAR attribute has not been exploded yet, there are still concatenated entries for the newly exploded TYPE attribute under TYPEAR. Performing the 2nd Exploder on _listTYPEAR{} creates too many features.
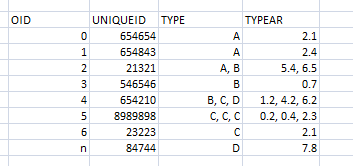
As an example, looking at row 3 in the above table, there should be two features as thus;
- 21321----A----5.4
- 21321----B----6.5
- 21321----A----5.4
- 21321----A----6.5
- 21321----B----5.4
- 21321----B----6.5
Does anyone know how to solve this?
thanks