

Hi,
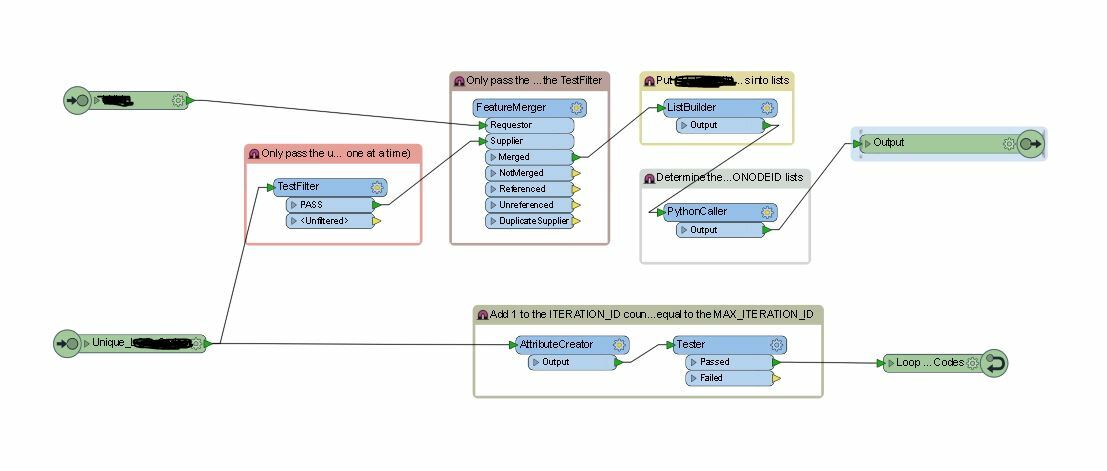
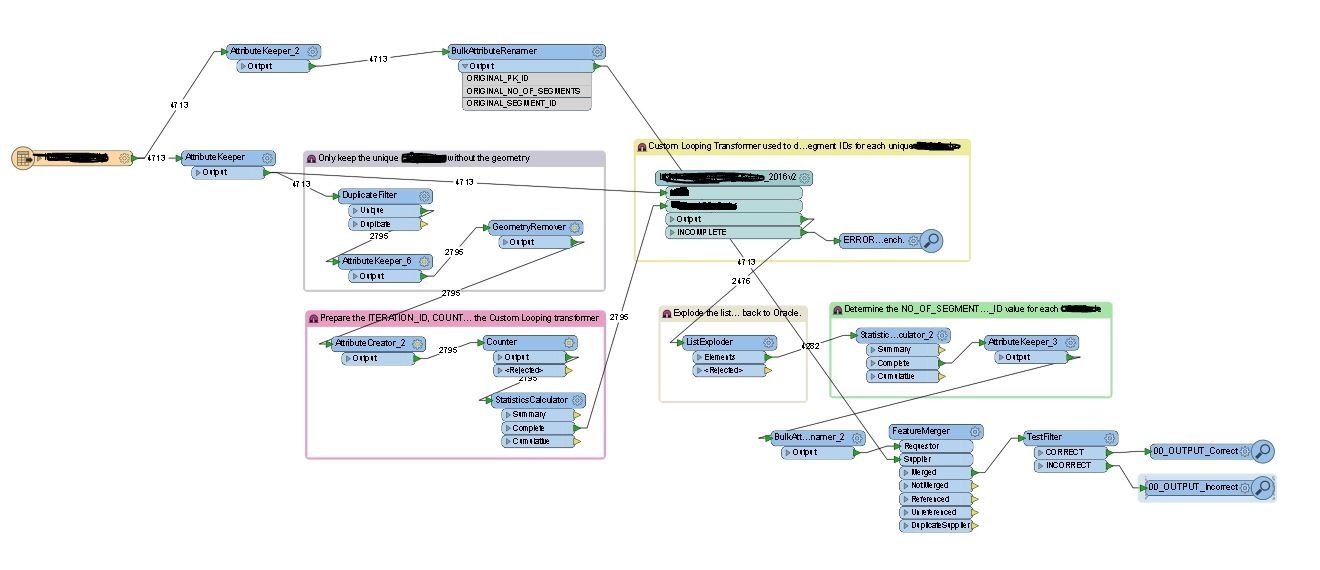
I have a FME 2016.1 workbench that contains a Custom Loop transformer and within that I also have a PythonCaller with some Python Code.
The workbench outputs the expected result but it takes over an hour to run. I need it to run ideally in less than 20 minutes.
I have attached some screen shots of the main workbench and the custom transformer. Does anyone have ideas on things I could do to speed this up?
Thanks,





