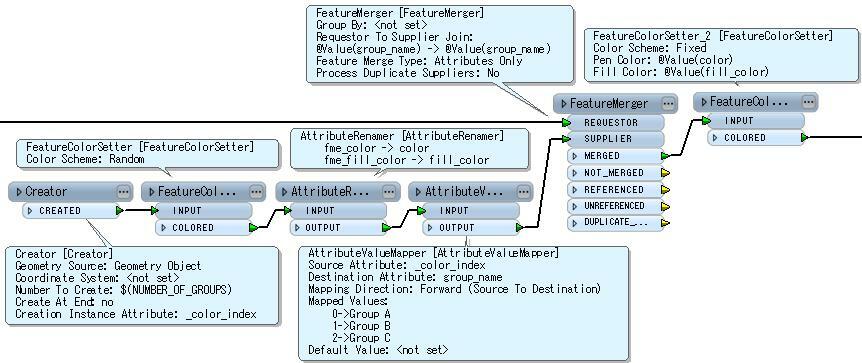
At the moment I'm achieving this by taking the data, using a duplicateremover so there is one instance of each group, a featurecoloursetter with the color scheme set to random, an attributekeeper to keep only the group attribute and the colour and then a featuremerger to merge the data back with the original data so that all features that share a certain attribute value have the same colour.
It seems a bit long winded and I'm wondering if I've missed a better way to acheive this.