



Hi,
I am wondering if someone can give me some ideas on how I could pass the result of a sql query from a sql executor so that the result or specifically an ID is passed sequentially so that each is fully processed before the next one starts.
So the result is as shown below. The attribute I’d like to pass one by one is either the device_id or the row_index.
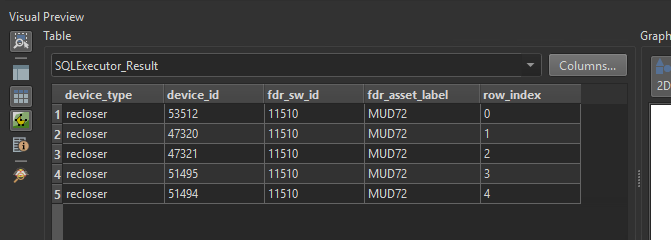
I have had a look at this post iterating/looping a workspace using attribute values | Community but cannot formulate the workbench to do this task.
Any suggestions very welcome.
Thank you.
fb





