Hi,
Situation - Oracle Writer will not work, so I need a workaround to overcome this. The tables in the workspace have many attribute fields, 2100 or thereabouts, and the Oracle writer falls over. 😕 Safe recommend upgrading to a newer Oracle, so the client will get that sorted eventually… but meanwhile I need to get the workbench working.
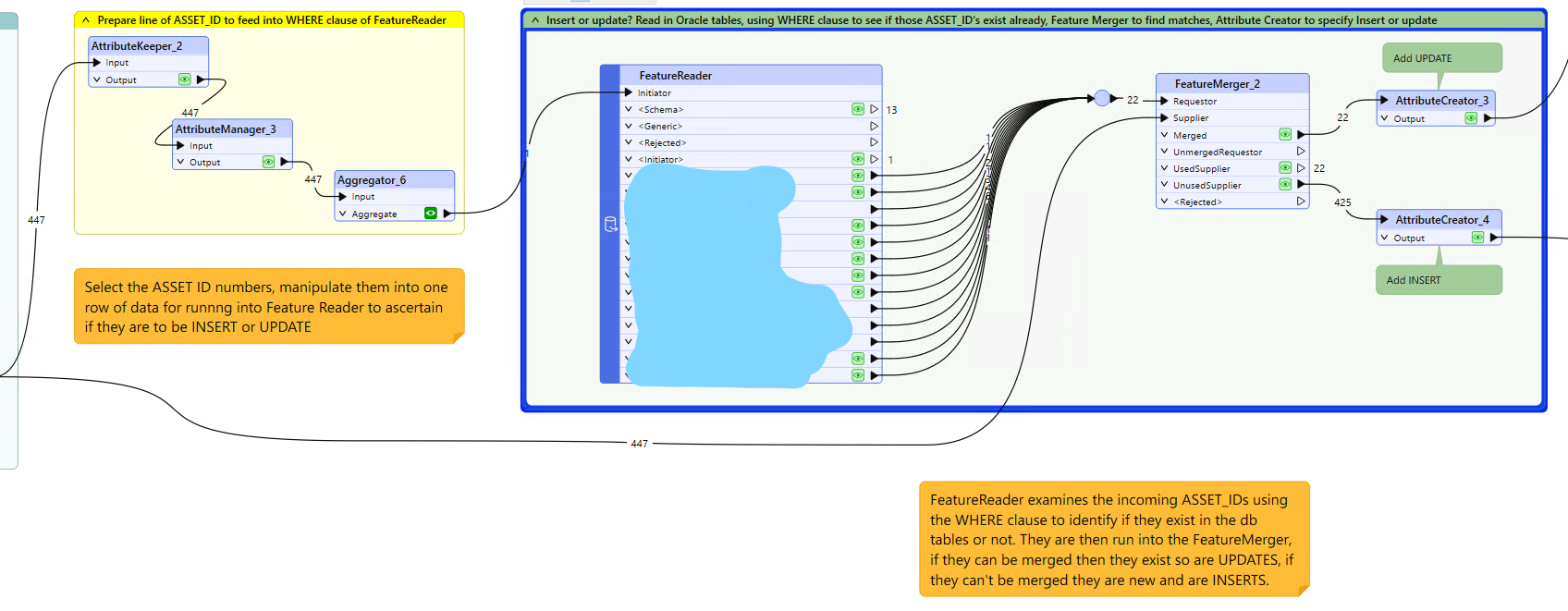
The workbench prepares delta files to be written into the Oracle db. Once the data is ready for writing to the db I have used FeatureReader to read 13 Oracle tables into the workspace, then use a FeatureMerger with the existing workspace table to identify if the features already exist in the 13 db tables or not. If they are UsedSupplier they exist and are then designated to be an “Update”, if they are UnusedSupplier then they are new features and are sent as an “Insert”.
As a further complication, we need to write to CSV files to overcome the issue with not being able to write to Oracle from FME. So we need a batch of csv files for Insert, and another for Update. Oh yeah, this is a fun one! 😁
This worked ok to begin with, but as the db has grown in size it takes hours to read in those large Oracle tables.
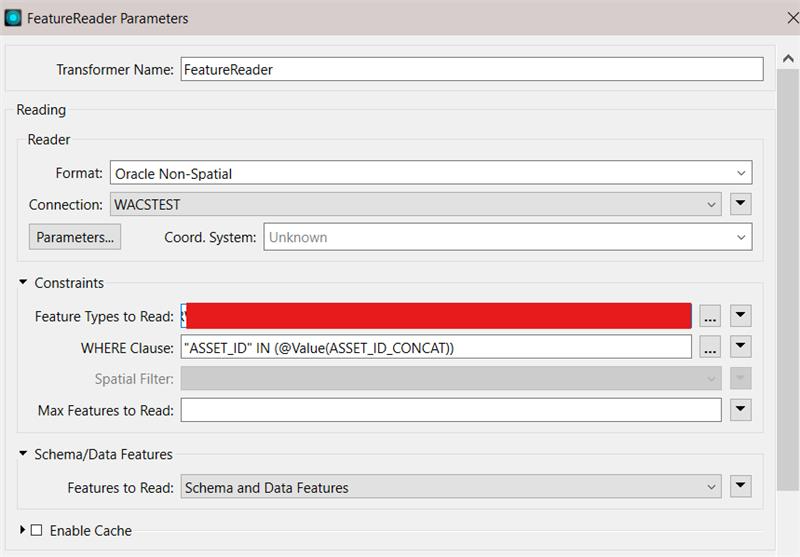
The tables each contain 100,000s of features. The delta files may only be around 5 to 30 features that need writing across. Is there a way to use the WHERE clause in the Feature Reader to pick up the unique identifier (ASSET_ID) from the FME workspace table so that only those 5 to 30 features are read in by the FeatureReader… if they exist? I presume that will be quicker than bringing-in all 13 whole tables into the workbench?
I’ve been using the AI engines to try to figure it out, and it seems that it is entirely achievable, but I can’t fathom out exactly how to do it! If you do have any bright ideas, please do not worry about overexplaining it, I need all the help I can get! 😳
Or is there a better way than using the FeatureReader? The AI engines reckon InLineQuerier is an option, but I am completely lost when trying to use that one.
Thanks in advance for any help you can offer.
Stu

")