



I've just had a support request which reminded me of an issue I had a few months ago using a looping transformer to page through HTTP requests, where I was ending up with more data than expected. The cause was the reusing a list attribute and I'd like the communities opinion on whether this behavior is a bug or just something to be aware of.
You can see what is happening with a simple workspace like
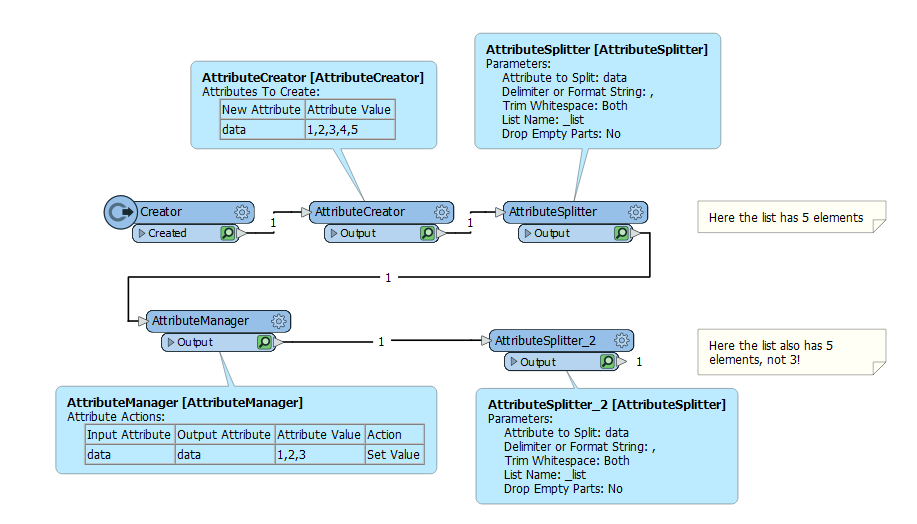 when the _list attribute is reused in the second AttributeSplitter it is not getting cleared before hand so it is retaining the 4 and 5 from the first AttributeSplitter.
when the _list attribute is reused in the second AttributeSplitter it is not getting cleared before hand so it is retaining the 4 and 5 from the first AttributeSplitter.
It's easy to correct once you know what is happening but it can cause some head scratching to debug, particularly in a looping transformer. Should anything that creates a list clear out any existing data first or are their situations were this behavior is wanted?

