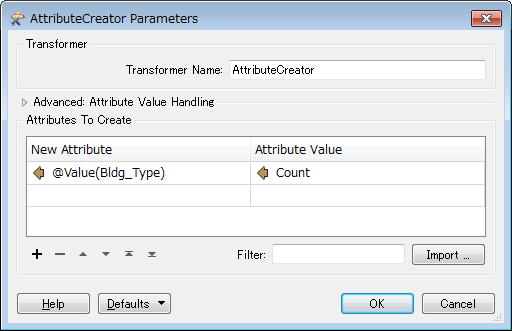
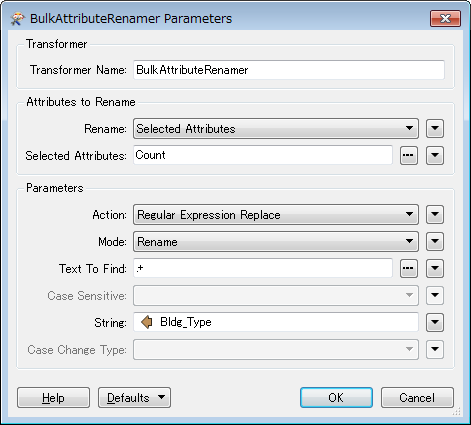
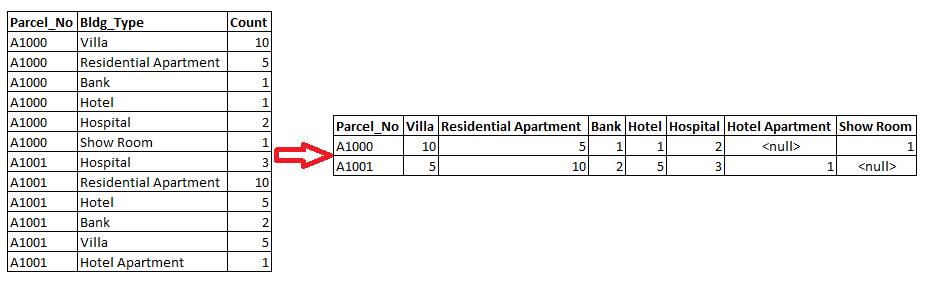
I have a table information and that needs to be transpose like shown below screen shot.
Parcel number is more then 1000 and each parcel bldg type up 30 plus types.
Please can advise to achieve this task.
Thanks in advance
Venu

 +5
+5I have a table information and that needs to be transpose like shown below screen shot.
Parcel number is more then 1000 and each parcel bldg type up 30 plus types.
Please can advise to achieve this task.
Thanks in advance
Venu
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.