



Hi list.
I have a master workspace in Workbench, which starts with a Creator calling two SQLExecutors, and eventually calls two WorkspaceRunners.
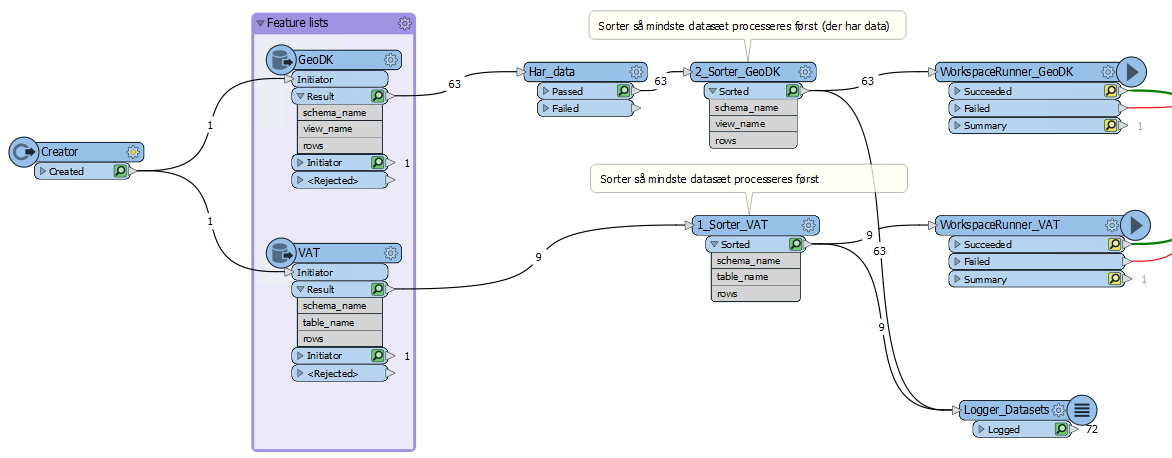
Each SQLExecutor fetches a list of tables in a dataset, adding their feature count (numbers of rows).
I specifically tell FME to process the smaller dataset (i.e. its SQLExecutor) first, but each “thread” also have a (blocking) Sorter transformer (sorting by feature count) before calling (its) WorkspaceRunner.
It seems that the result from the two blocking Sorter transformers are processed by FME in the wrong order regardless of which order the features have arrived.
How can I ensure that the Sorter for the smaller dataset (i.e. VAT above) executes first, before the Sorter for the larger dataset ?
As is seen, I tried to rename the Sorters, so the smaller was alphabetically listed before the larger, but it didn’t change anything. The Logger logged the larger dataset first.




