Hi there,
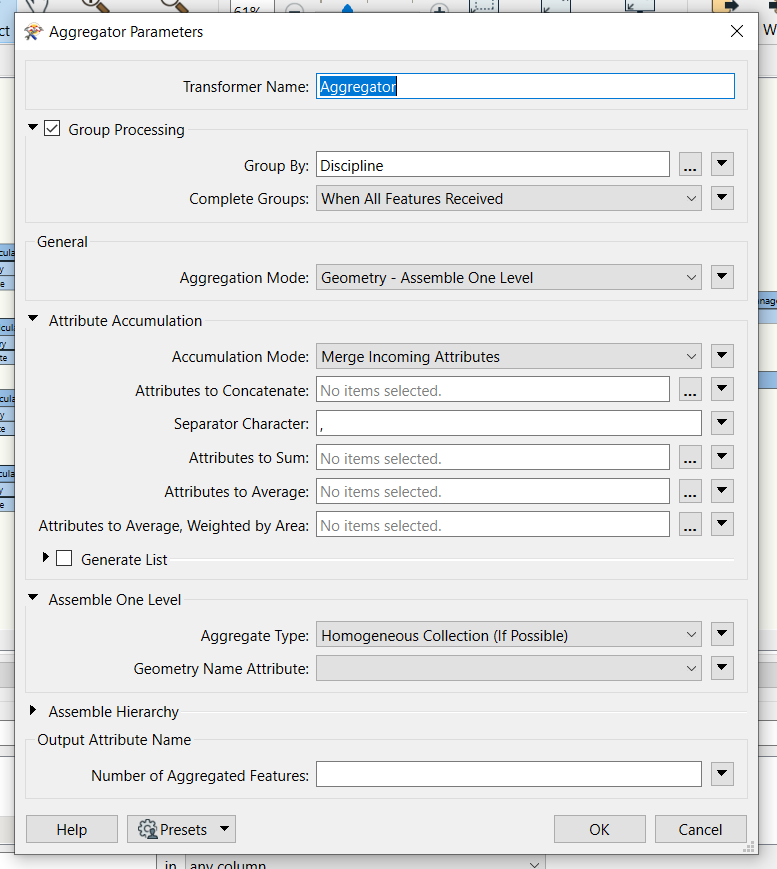
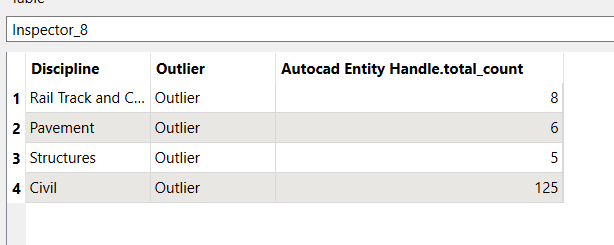
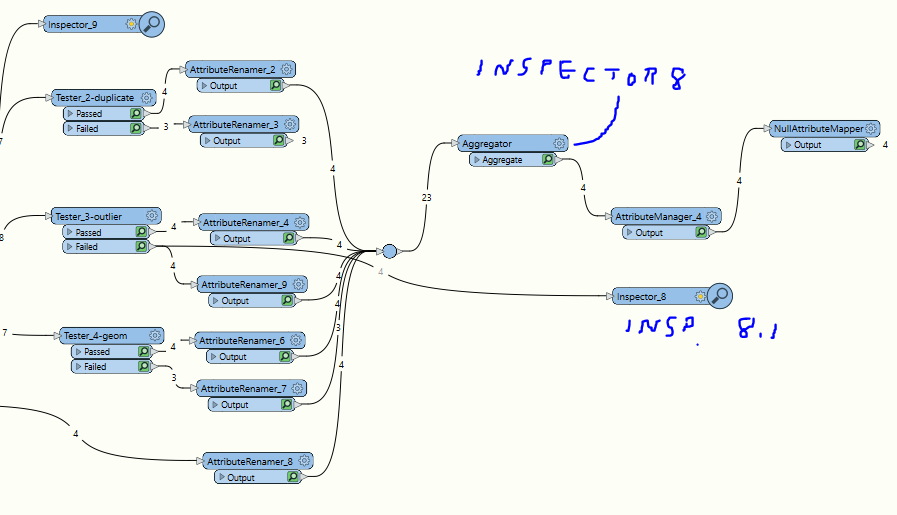
This one is fairly simple, I want to combine so the duplicate count is on a single row for each discipline feature:
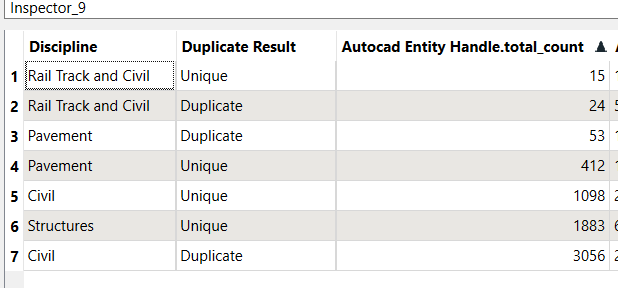
should look like:
Duplicate Unique
Rail Track and Civil 40 22
I've tried aggregator and attributepivot and haven't quite got it across the line!
Cheers!