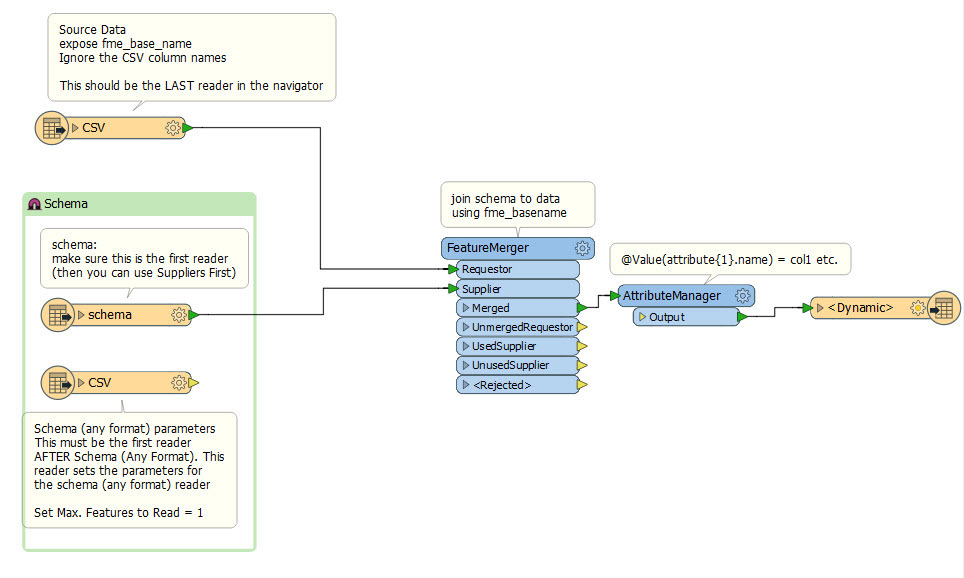
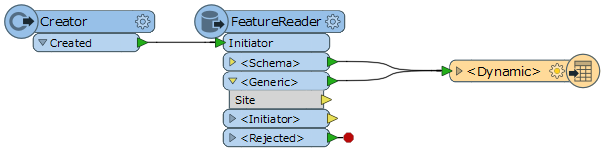
Hi
I have a workbench that takes a csv file and creates 10 csv files , 1 for each site - it does this using AttributeFilter.
This works great but the csv reader gives the last 8 months of data with each month as a column. So the first version we ran had Nov to Jun. This latest month is Jan to Aug. So every time we run this the attributes change and I had to manually update this last time.
Is there a way of automatically picking up new attributes from the reader and adding them to the writer (and removing any no long needed) please?
I'd ideally like to schedule this with server but I can't unless this is automatic.
Thanks