")

There's a number of other similar posts out there, but I can't seem to find a solution that works. I'm still trying to build a workflow for this on my end, but I figured I'd post here to see if anyone knows of an easy solution.
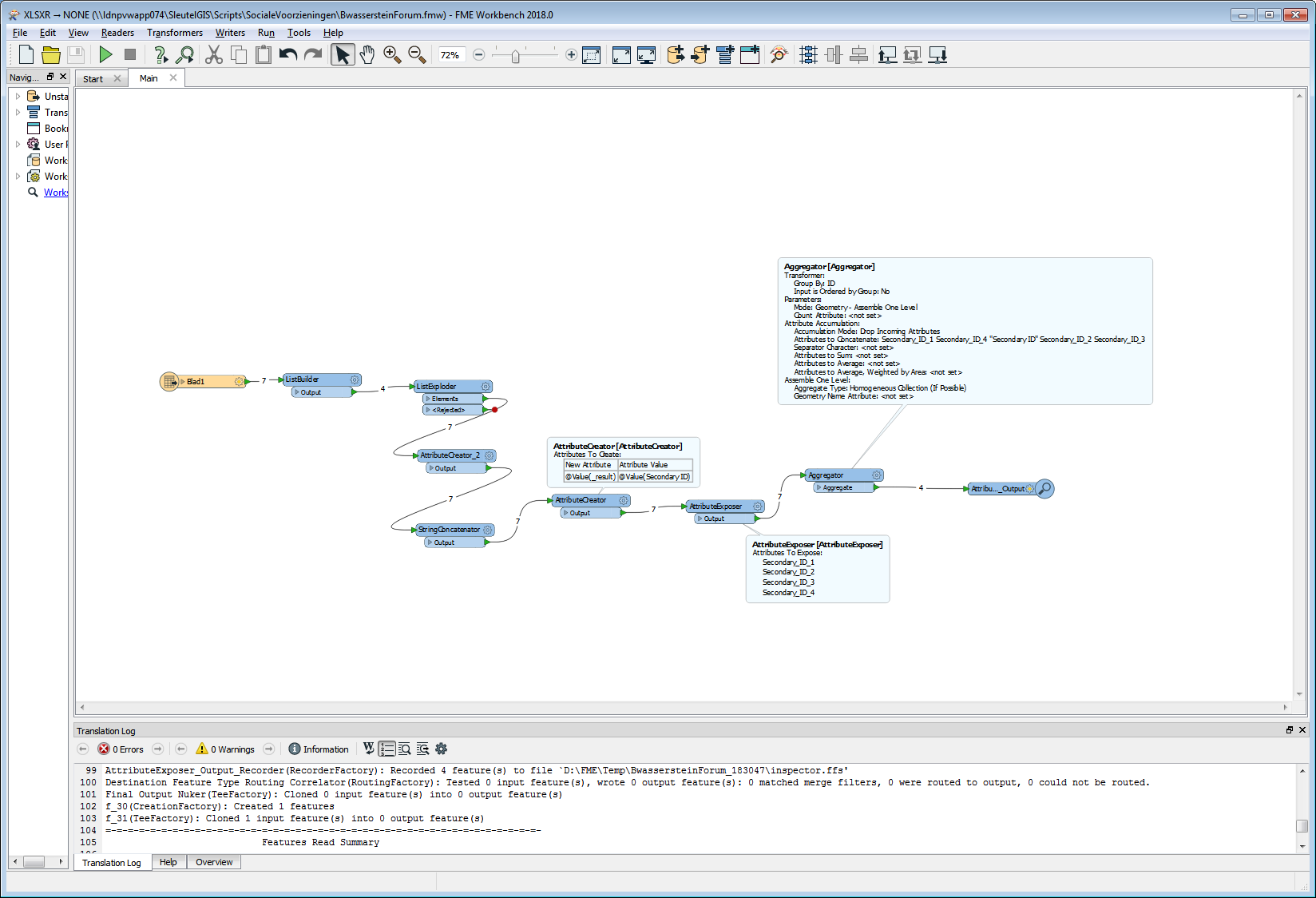
I have data in a table that looks as follows...
IDSecondary ID1ABC1231DEF3451GHJ6782DEF3452XYZ7893VWX5674ABC123
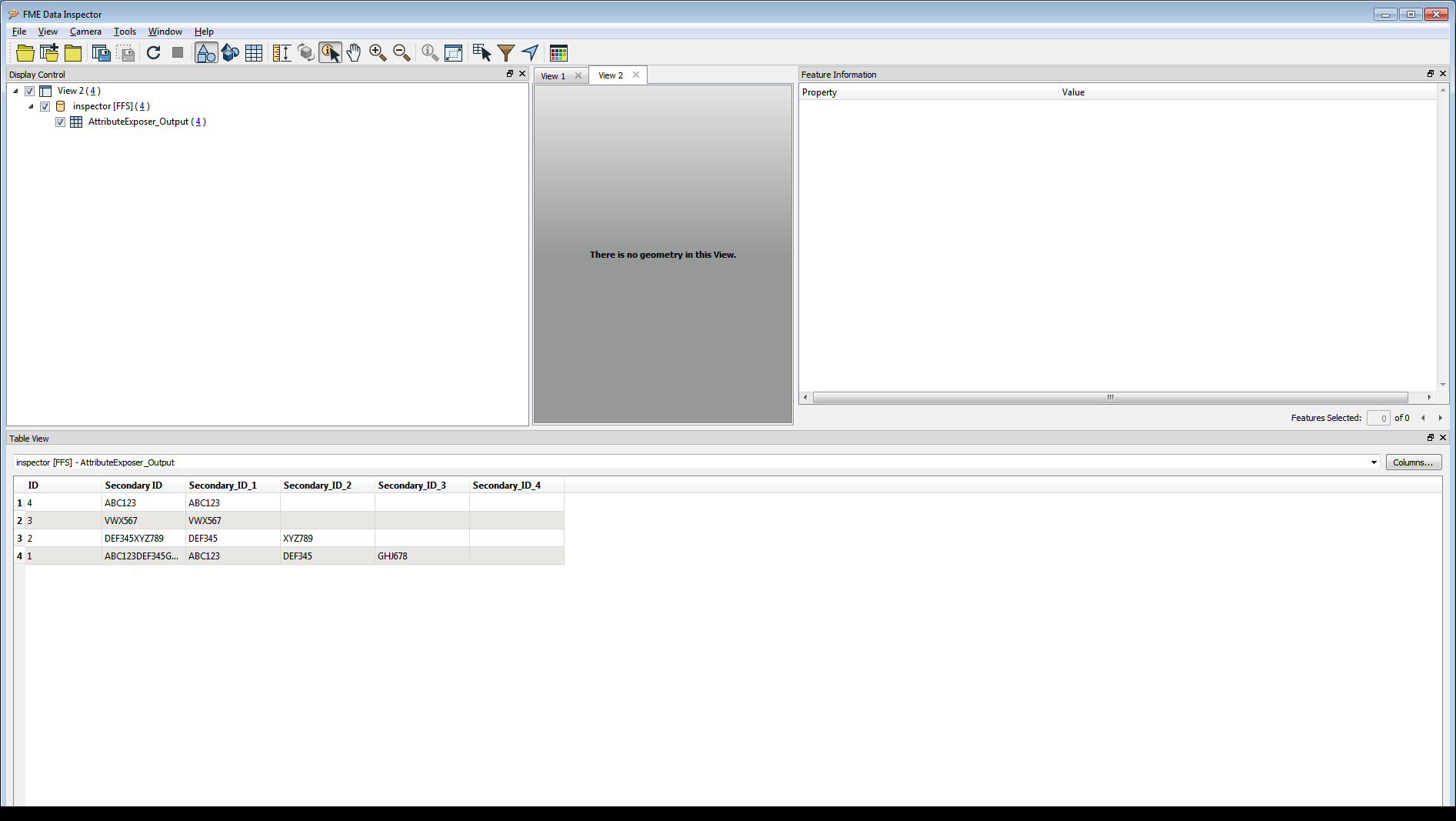
And I'd like to transpose this across a spreadsheet so that it looks as follows...
IDSecondary_ID_1Secondary_ID_2Secondary_ID_31ABC123
DEF345
GHJ678
2DEF345
XYZ789
3VWX567
4ABC123
The problem I'm hitting a wall with is that there may be any number of Secondary_IDs for a given ID...potentially a couple hundred for a single ID. So, I'm looking to have a tabular data set in the end that may have a couple hundred columns, with a single row for each ID.
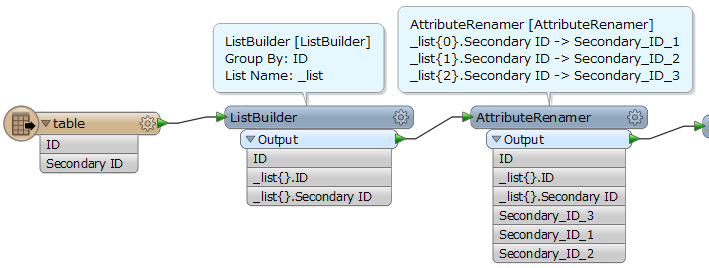
Is this possible? I'm trying to wrap my head around using list attributes, but am struggling to find a solution to output each attribute value in a list as it's own column. I only need one list attribute for the Secondary_ID values as far as I'm aware.
I'll keep playing around and I'll post any solutions that I find.
Thanks for your time.
FYI...I'm running FME 2015.0 (20150114 - Build 15245 -WIN32) via ArcGIS data interoperability extension.