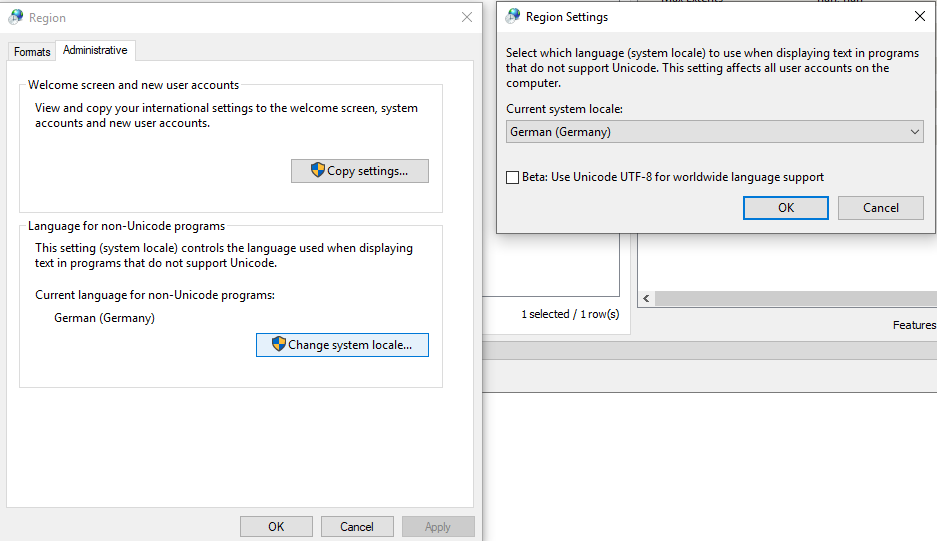
This is probably rather a Windows 10 problem but maybe someone can help: If I use the StringLength function I get wrong counts for words with German special characters (e.g. "Ä" or "ß") because they get a length of 2 instead of 1. When I ran the same workspace on a colleagues machine the length was calculated correctly so I guess I have to change some region or language settings but so far I could not find the culprit. Any idea what's the issue here? Thank you for any help.
Edit: For some reason the StringLengthCalculator Transformer calculates the right length.