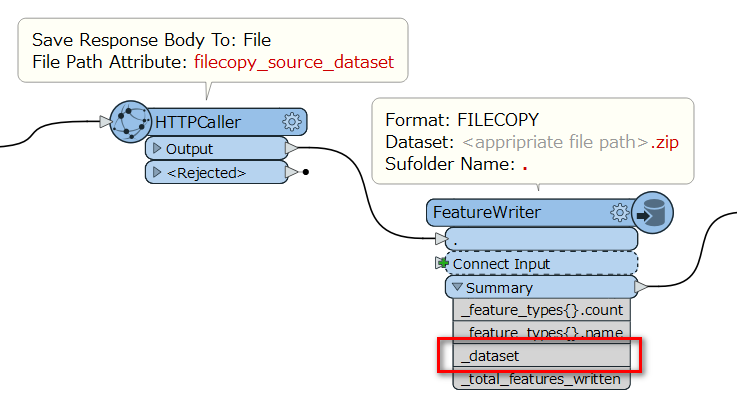
Hi FME'ers,
I am using the HTTP caller to download multiple CSV files to a folder. I'd like to zip the folder and output the zip folder path as a single features to a automation writer. Can this be done? The automate writer would then trigger a second workbench to read all the CSV files and process them. I don't want to automation writer to trigger this workbench per file.
Thanks,
David