Hello everyone,
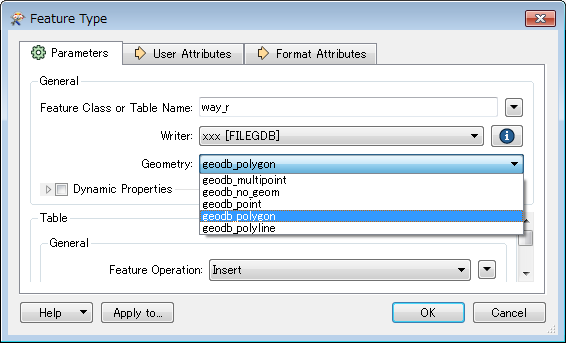
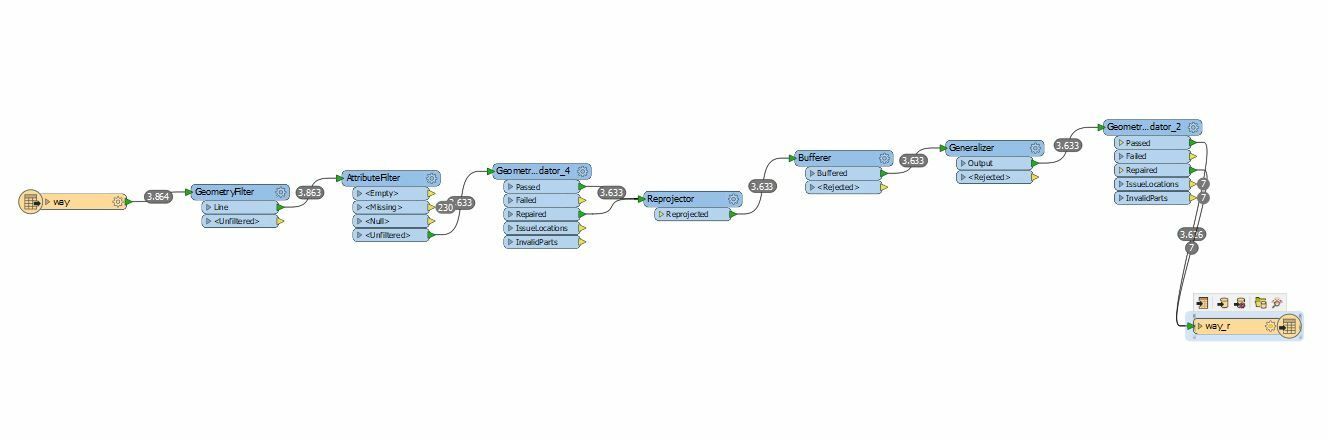
I am working with line geometry as a reader. Then i buffered the line feature and used generalizer (with Algorithm: Douglas Generalize, share boundaries: No, Tolerance:30), to simplify the buffered line feature and need a output with Esri Geodatabase (File Geodb API).
But it shows the errors:
Failed to write Geometry to feature class 'way_r' with geometry type 'esriGeometryPolyline'. Dropping containing feature
I have also attached the ERROR text. Please help me.
Thanks.