


We have some automatic data-updates on an ESRI File Geodatabase. I also want to update some parts of the metadata also automatically as part of the update procedure. I want to change Edition, Publication date, Revision date and dataset ID.
I succeeded getting the right information to insert in the XML updater, but the XML updater doesn't seem to do anything in the metadata. I don't see any result. Could anybody help me out? I added the workspace to this question.
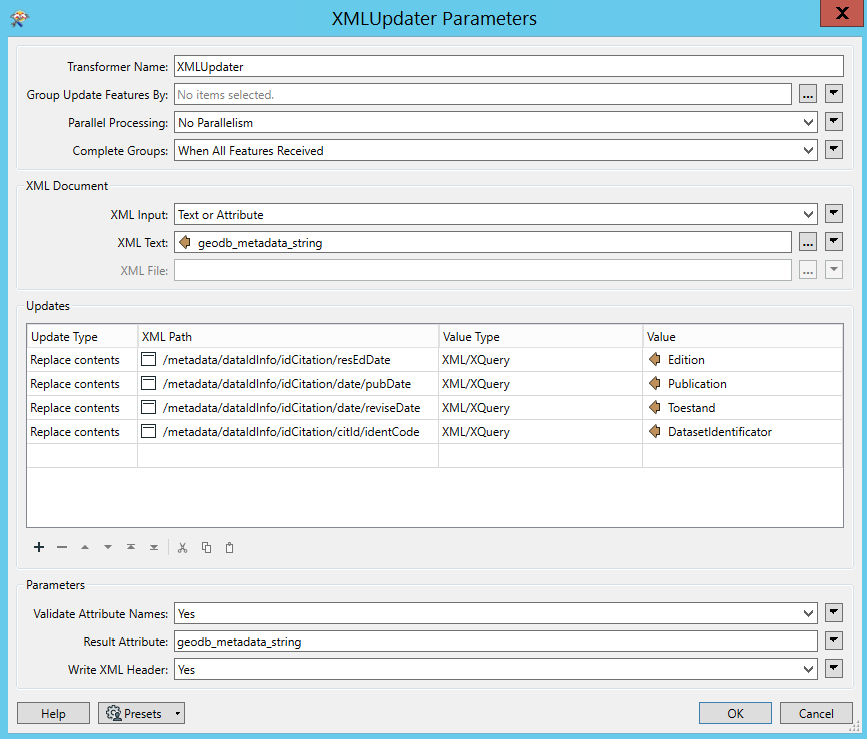 Addition 9/12/2022:
Addition 9/12/2022:
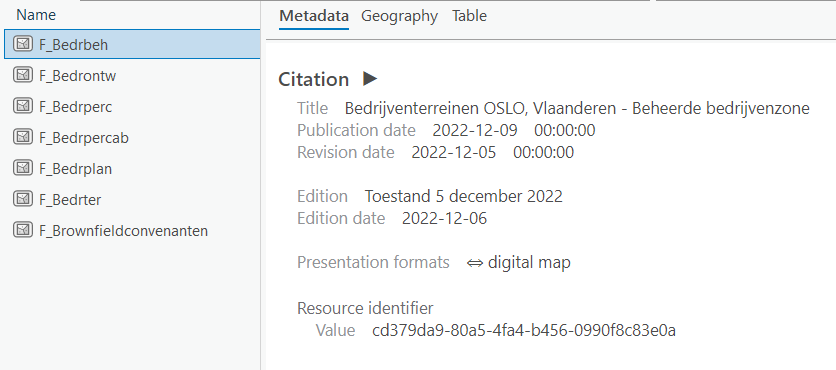
I just discovered that, if I fill out these fields manually in ArcGIS Pro, that this information is not found in the metadata that is read by FME. This is what's filled out and seen in ArcGIS Pro:
 I used the mehod with the XML Formatter to see what's in the metadata, and this gives the log attached. You'll see the information shown in ArcGIS Pro, can not be found in the XML read by FME.
I used the mehod with the XML Formatter to see what's in the metadata, and this gives the log attached. You'll see the information shown in ArcGIS Pro, can not be found in the XML read by FME.
 Exporting the metadata out of ArcGIS Pro to XML, contains other (and right) information:
Exporting the metadata out of ArcGIS Pro to XML, contains other (and right) information:
<identificationInfo>
<MD_DataIdentification>
<citation>
<CI_Citation>
<title>
<gco:CharacterString>Bedrijventerreinen OSLO, Vlaanderen - Beheerde bedrijvenzone</gco:CharacterString>
</title>
<date>
<CI_Date>
<date>
<gco:Date>2022-12-09</gco:Date>
</date>
<dateType>
<CI_DateTypeCode codeList="http://www.isotc211.org/2005/resources/Codelist/gmxCodelists.xml#CI_DateTypeCode" codeListValue="publication" codeSpace="ISOTC211/19115">publication</CI_DateTypeCode>
</dateType>
</CI_Date>
</date>
<date>
<CI_Date>
<date>
<gco:Date>2022-12-05</gco:Date>
</date>
<dateType>
<CI_DateTypeCode codeList="http://www.isotc211.org/2005/resources/Codelist/gmxCodelists.xml#CI_DateTypeCode" codeListValue="revision" codeSpace="ISOTC211/19115">revision</CI_DateTypeCode>
</dateType>
</CI_Date>
</date>
<edition>
<gco:CharacterString>Toestand 5 december 2022</gco:CharacterString>
</edition>
<editionDate>
<gco:Date>2022-12-06</gco:Date>
</editionDate>
<identifier>
<MD_Identifier>
<code>
<gco:CharacterString>cd379da9-80a5-4fa4-b456-0990f8c83e0a</gco:CharacterString>
</code>
</MD_Identifier>
</identifier>
Any idea how this is possible? Or any tricks to help me out ?








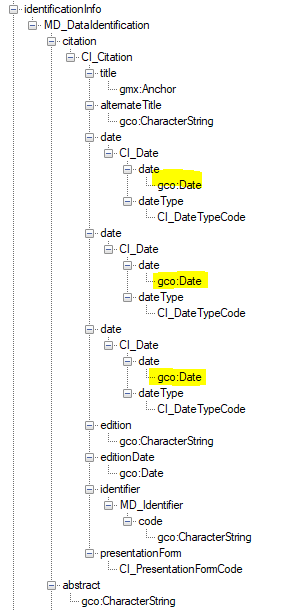 So, //idCitation//date is not clear ... How do I find the correct xpaths?
So, //idCitation//date is not clear ... How do I find the correct xpaths? 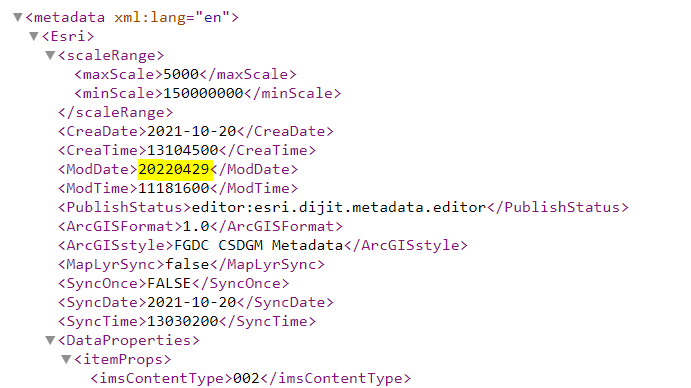 The xpath would be: "//Esri//ModDate" (this would retrieve the element object). To actually pull the date text out (20220429), you would add the xpath command: text(). So the xpath would now be: "//Esri//ModDate//text()" which would give us the date text in a list and if we were to print it out, you would get ['20220429']. You can then use python list indexing to then pull the actual date value out like in my previous example by adding [0].
The xpath would be: "//Esri//ModDate" (this would retrieve the element object). To actually pull the date text out (20220429), you would add the xpath command: text(). So the xpath would now be: "//Esri//ModDate//text()" which would give us the date text in a list and if we were to print it out, you would get ['20220429']. You can then use python list indexing to then pull the actual date value out like in my previous example by adding [0].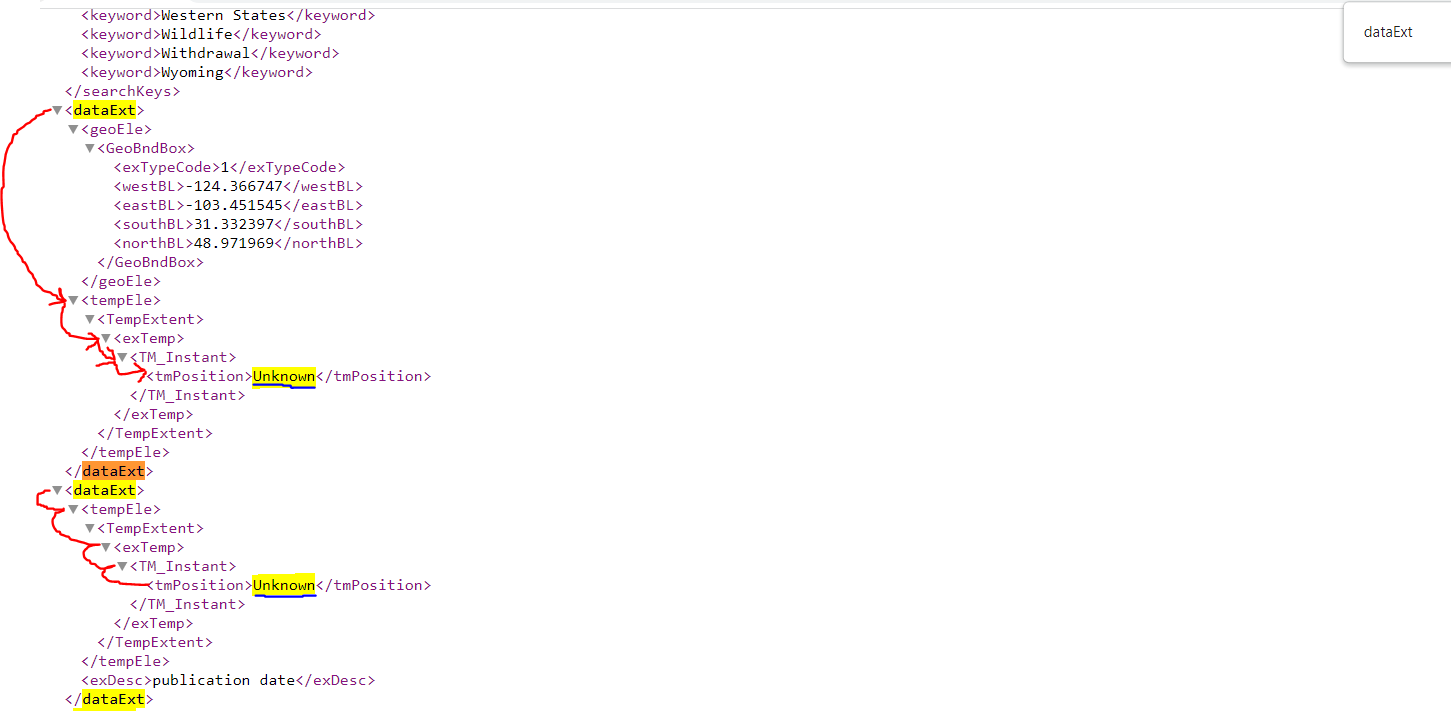 Following the xml structure here, We would use the xpath: '//dataExt//tempEle//exTemp//TM_Instant//tmPosition//text()' which would give use a list of all the tmPosition text elements. In this example, we would get a list of ['Unknown', 'Unknown']. Now that we confirmed we got our xpath right, you could then update both 'Unknowns' by doing something like this:
Following the xml structure here, We would use the xpath: '//dataExt//tempEle//exTemp//TM_Instant//tmPosition//text()' which would give use a list of all the tmPosition text elements. In this example, we would get a list of ['Unknown', 'Unknown']. Now that we confirmed we got our xpath right, you could then update both 'Unknowns' by doing something like this: There is a lot of different ways to approach this but hopefully, this helps!
There is a lot of different ways to approach this but hopefully, this helps!