I have lots of files (read into FME 1 by 1) within which there are details of lots of polylines, this detail consist of:
1) A LineID
2) A set of coordinates that build the line.
It looks like the LineIDs ARE sorted, but the coordinates are supplied with a vertex number and these are definitely not sorted.
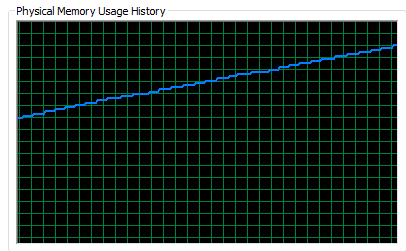
I have to use a Sorter, but this is a major bottleneck and even with a few hundred thousand rows of data the memory usage is climbing unnervingly. When I throw the real data at the process I'm not confident that it won't fall over at some point.
What I'd like to do is only sort coordinates for LineIDs on a per file basis. So every time a new filename arrives on a feature that lets the Sorter know to release the existing 'sorted' features that had a different filename and let them pass on through the process.
I tried to create a GroupedSorter by wrapping a Sorter up as a custom transformer and exposing the Parallel Processing Group parameter, so that I could group by fme_basename. This hasn't worked, all the features are still trapped till everything has been sorted.
Please help me avoid this, it's giving me sleepless nights: