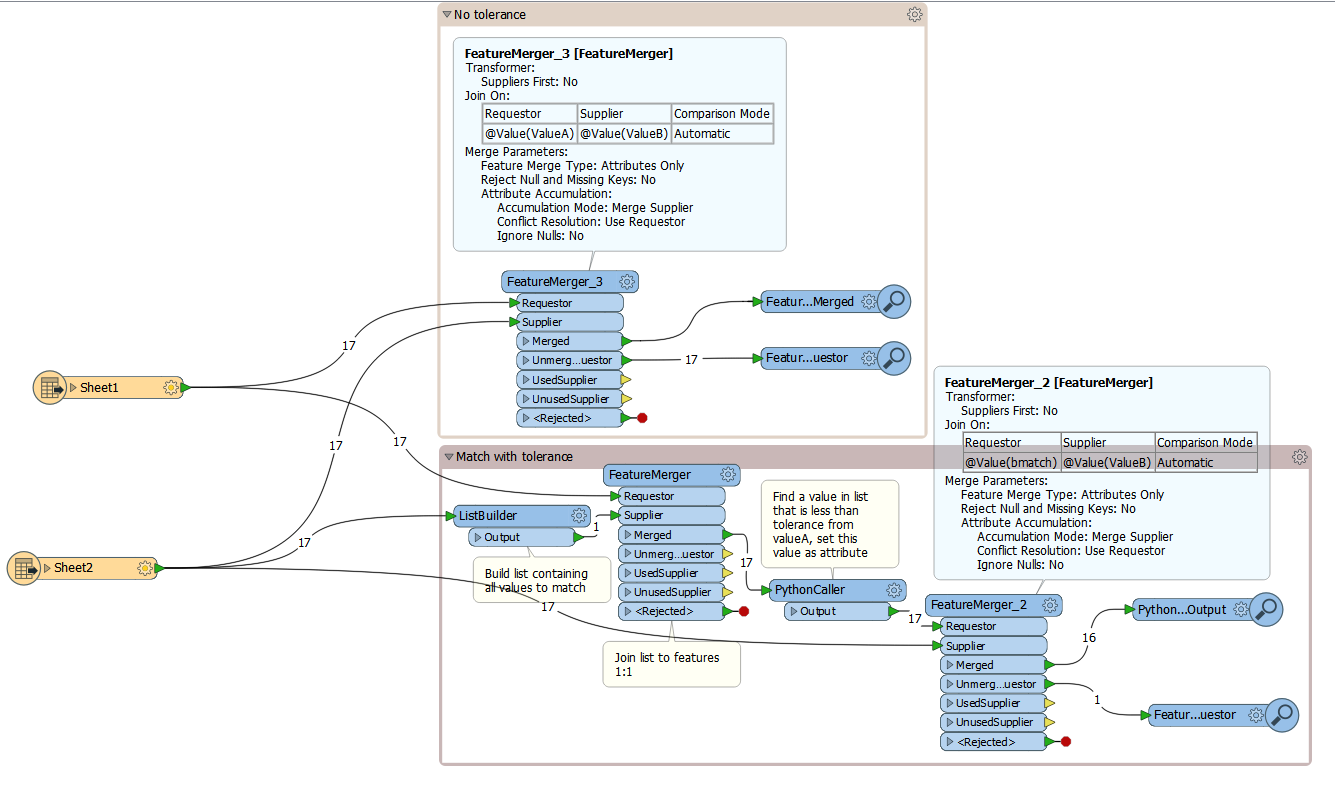
I would like to join features from two data sources based on a datetime attribute. However I would like to apply a tolerance as the rounding varies ever so slightly in the two datasets. So for example a feature in one dataset has a datetime of 20140922150020.782, while in the other dataset it is 20140922150020.783. These are essentially one and the same, however there is no "tolerance" setting in FeatureMerger for something like this: it is a very "black & white" transformer :) Are there any other workarounds or techniques for this sort of problem? I could truncate the above to 2 decimal places, but that is a bit risky for this application. A tolerance of +/-0.001 for example would do the trick. Thanks.

Question
Tolerance in FeatureMerger
 +6
+6This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.













Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.