
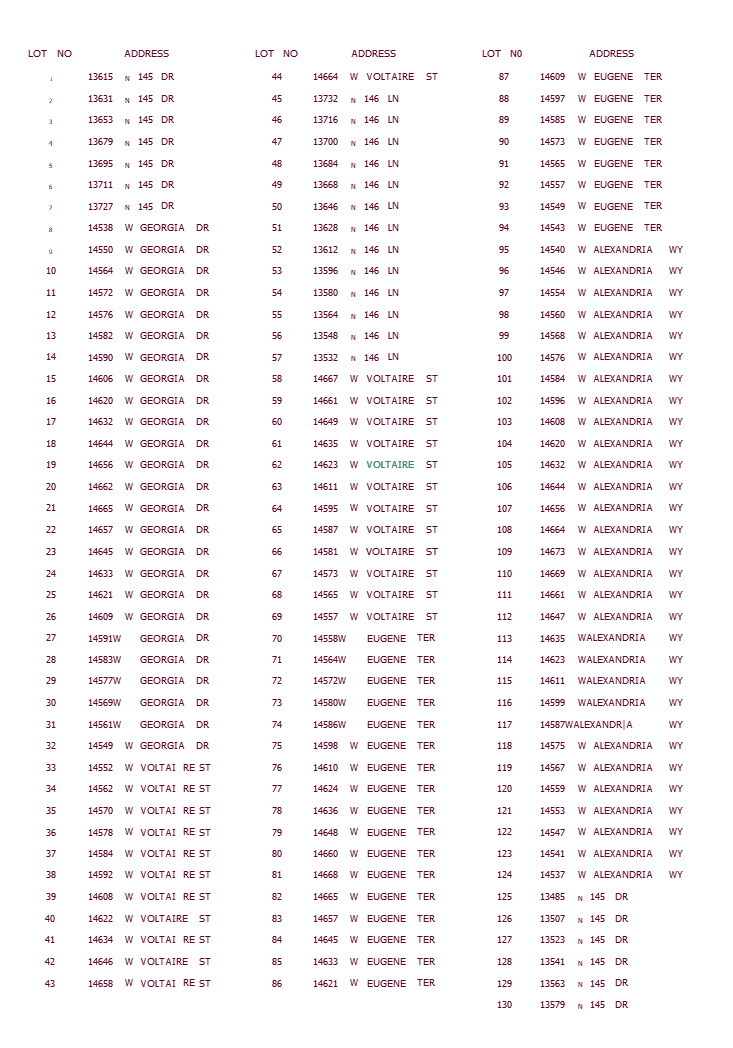
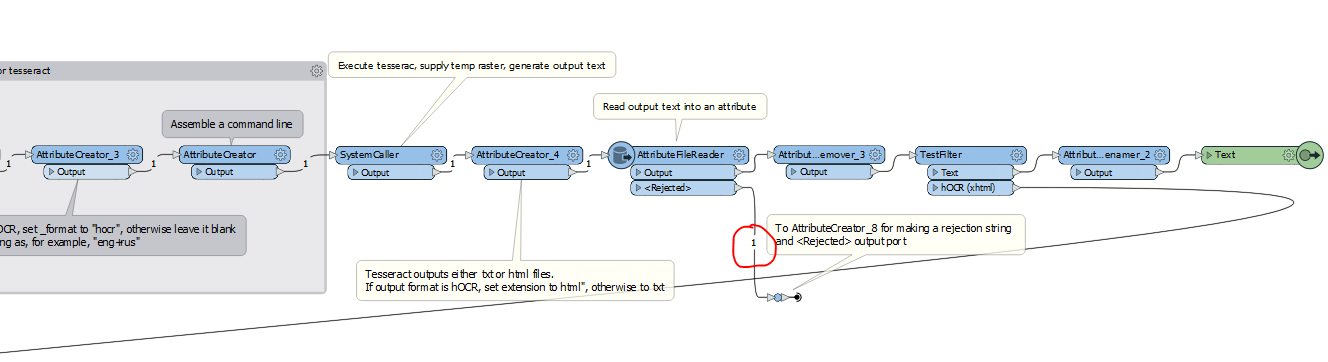
I am trying to extract text from a table in a PDF image using the TesseractCaller. But only part of the table values are being returned. The text for the document is the same font and size and the contrast is the same for the entire document. Does anyone have any hints or tricks to get tesseract to return the complete table?

Question
The TesseractCaller only returns 75% of the image. Are there any parameters I can adjust to get all of it?
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.




")


")
Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.