Hello,
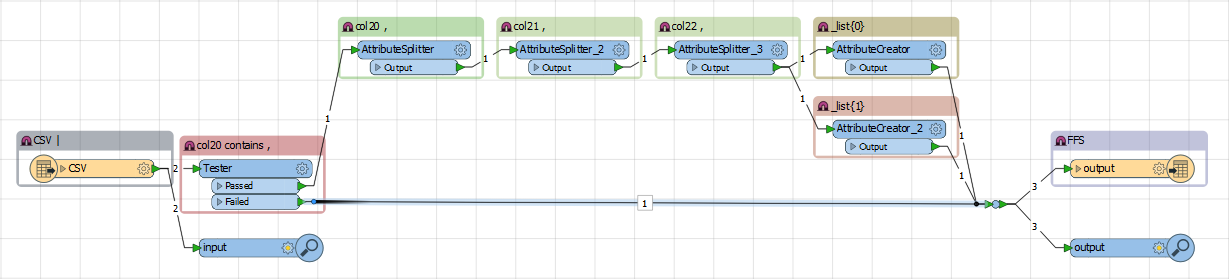
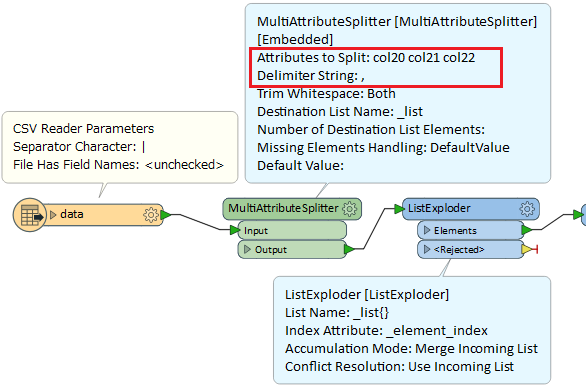
I have a CSV dataset that is mostly records like this, with a "|" delimiter
2185996|SP213604|1|C|P|UK|||||857||||GYMPIE|RD||CHERMSIDE|BRISBANE CITY|1000|-27.38682393|153.03160112|PC|GDA94
However, some of the records also have a "," delimiter
2388577|SP246762|6|C|P|UK||||WHELLER ON THE PARK|950||||GYMPIE|RD||CHERMSIDE|BRISBANE CITY|1000|-27.38253041,-27.380533|153.02547625,153.027633|PC,BC|GDA94
This is a dataset of street addresses and property points. Most points are "parcel centre" or PC. But some also have a "building centre" BC. These records have two lats, two longs and two types, separated by commas.
Is there a transformer in FME that will split each of these records into two records?