Hello,
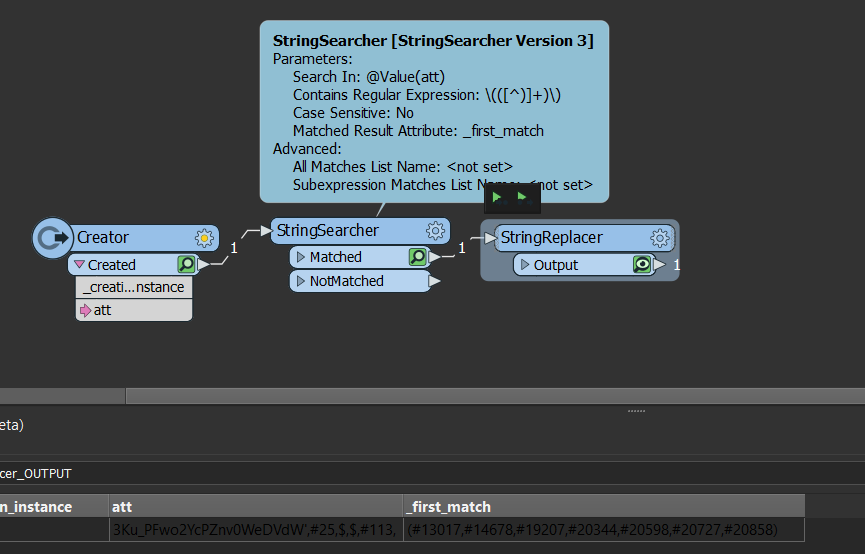
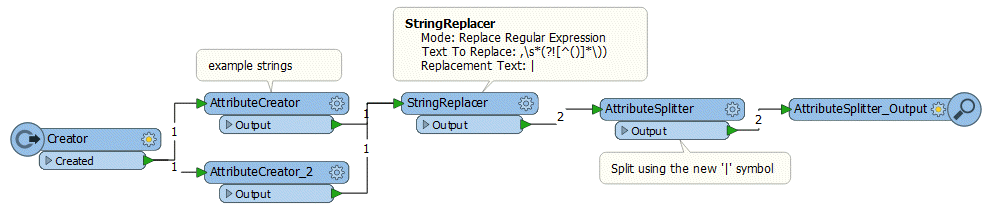
i'm trying to split an attribute into a list with the attributesplitter using a delimiter.
The problem is the same delimiter must sometimes be ignored.
The atribute i'm trying to split is:
'3Ku_PFwo2YcPZnv0WeDVdW',#25,$,$,#113, (#13017,#14678,#19207,#20344,#20598,#20727,#20858)
The list values should be:
0: 3Ku_PFwo2YcPZnv0WeDVdW
1: #25
2: $
3: $
4: #113
5: #13017,#14678,#19207,#20344,#20598,#20727,#20858
when using the delimiter "," the last values will also be split...
The problem also is that the format of the attribute differ each time. So sometimes it could be: $,$,$,($,$,$,),$,$,($,$,$),$ or $,$,$,$ of ($,$,$),($,$,$),$,($) etc...
The order of the list must remain the same as the original order.
Any suggestion would be more than welcome;)
cheers,
ronald