Hi community.
I have run into something that I am trying to automate but falling over at the last step.
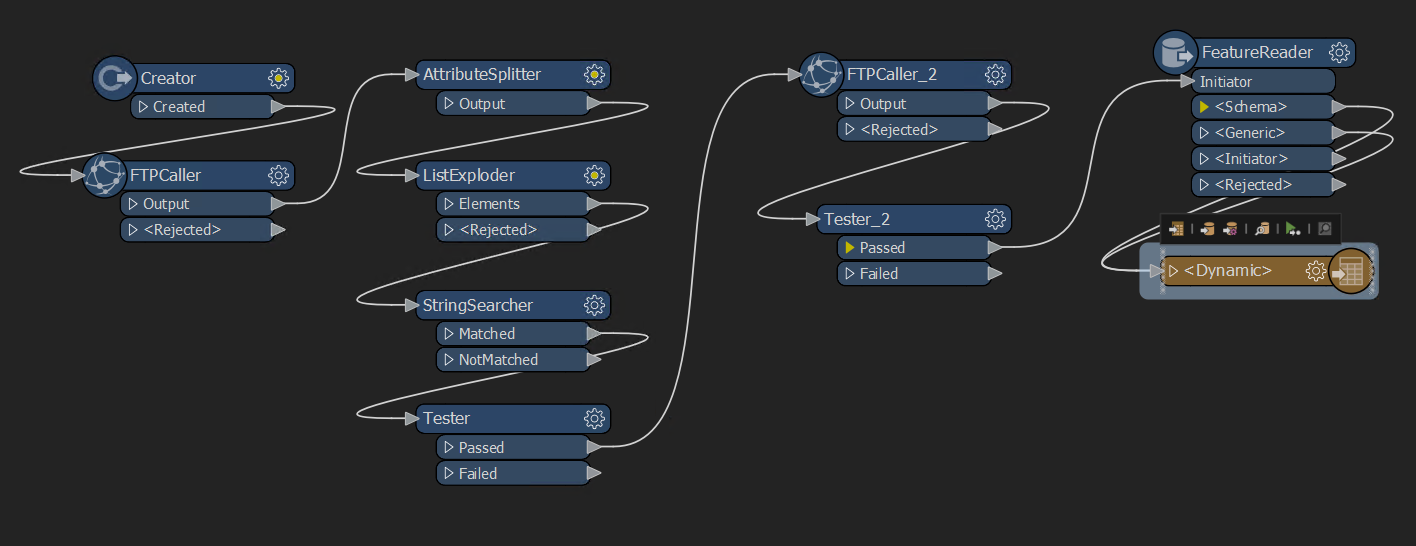
The process I have is:
- Download data-set names from FTP.
- Split data-set name list into attributes.
- Download data-sets from FTP to local drive.
- Read downloaded data-sets using the feature reader.
- Dynamically write data-sets into SQL server.
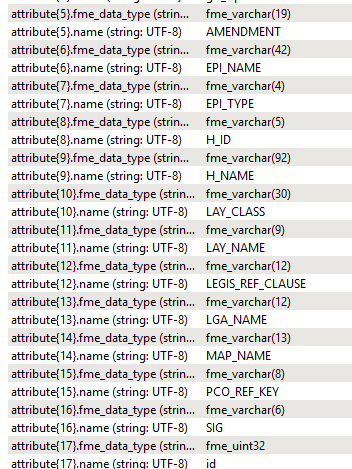
The last step I have missed is setting the primary key attribute for each data-set (fortunately it is the same 'ATTR_STR_1' for each data-set) as the dynamic writer is reading from the schema attributes coming out of the feature reader.
Has anyone had success with setting a primary key in dynamic writing?
I have tried a few things:
- SQL To run after write: alter table landmap_polygon add primary key (ATTR_STR_1)
- Error here is that the column is already populated and not set to no 'nulls' and I would need to set this for each table (we won't know table names until after the fact).
- Read schema from existing table (after setting primary key).
- The drop and create of the writer seems to ignore the primary key definition so the table is created without the key.
- Run read/write in a second workbench to a static schema.
- Works well but this means running and maintaining two workbenches.
- Altering the schema to add a 'type' of 'primary key' to the schema list for the ATTR_STR_1 attribute and blank for others.
- This is the current solution I am working on but haven't had any luck yet.
Any suggestions?
Thank you all.