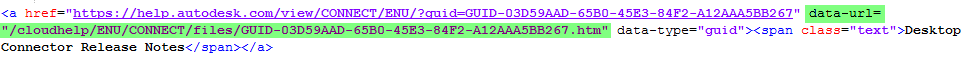I've seen similar questions asked here but cannot find real solutions. So here's what I'm trying to do..
I would like to get information from this page as an example: https://help.autodesk.com/view/CONNECT/ENU/?guid=GUID-03D59AAD-65B0-45E3-84F2-A12AAA5BB267.
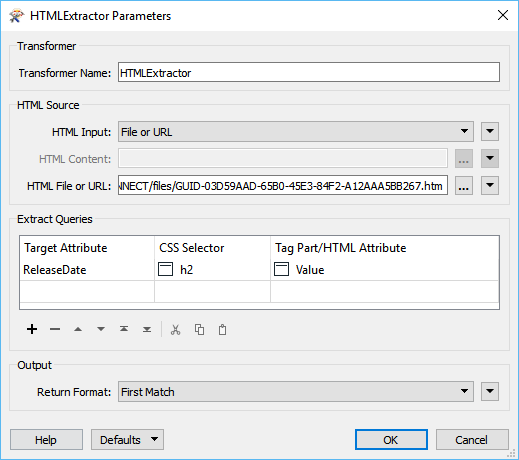
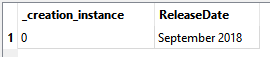
If you look at the page source, you'll see there isn't much valuable info. here and it seems to be using javascript to serve up the page (which updates when a new version is released, maintaining the original URL). If I use an HTTP caller with a GET method, I get the same page source. However I'm interested in the text you see in the loaded page. There are lots of sites out there built this way nowadays, which work in a very similar, dynamic way.
Is there a solution to get data from this kind of page? The only plausible (and costly) way would be to use some service such as parsehub.com (which I have not used or tested) where you could use their REST API to get data into FME: https://www.parsehub.com/docs/ref/api/v2/#introduction
Any other thoughts or tips would be greatly appreciated. Thanks!