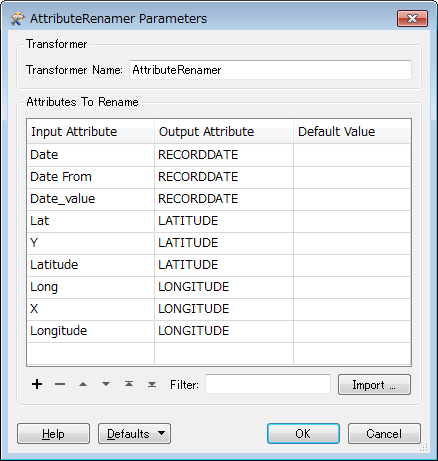
Hi, I need to import lots of different datasets into a database. The field names of the source datasets (i.e. reader) don't always match the field names of the destination database (i.e. writer). Therefore I'm using the SchemaMapper transformer. My external lookup table that SchemaMapper uses has all of the different field names of my source datasets, and the corresponding names for my destination database (see example below).
Source DatasetDestination DatabaseDateRECORDDATEDate FromRECORDDATEDate_valueRECORDDATELatLATITUDEYLATITUDELatitudeLATITUDELongLONGITUDEXLONGITUDELongitudeLONGITUDE
However, if my source dataset has a field name that already matches the field name of my destination database, then that field does not import into my destination database when I run my FME script using SchemaMapper. So using the example table above, if my source dataset has a field name "LATITUDE', then that field name will not import. Is there a setting in SchemaMapper to get around this? Or alternative easy fix? Or is it something I'm doing wrong?
Cheers, Damian