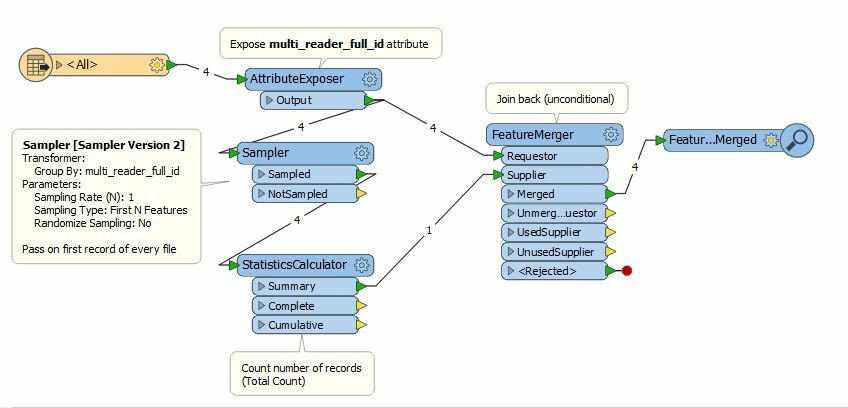
I would like to count the number of input files and return this number to be able to use it in an arithmetic calculations afterwards.
To be more precise, I have X Excel files, each containing values that are regularly repeated, but each with a different frequency. I calculated how many times each value occurred in all the files (so I have 2 attributes: value and count), and now I would like to divide each count by X (number of files) to get the frequency as a 3rd attribute.
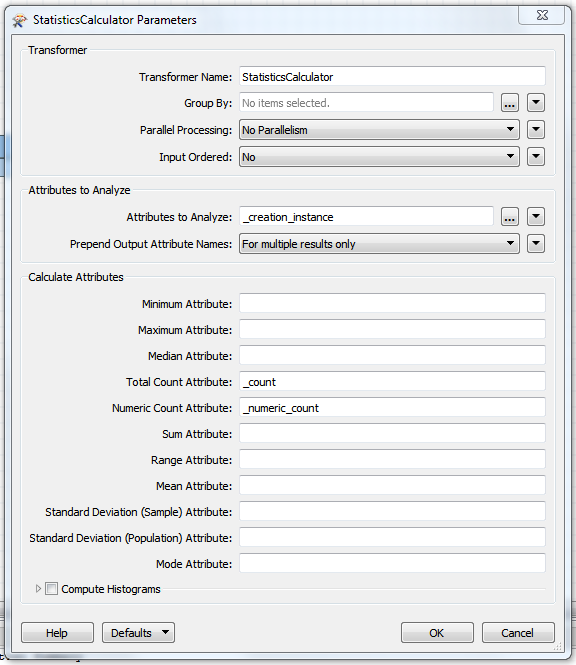
I tried using Aggregator, Statistics Calculator and Counter to get the number of input files, but I get 'missing' or 'null' values when I try to save it as an attribute. How can I 'save' or return this number?