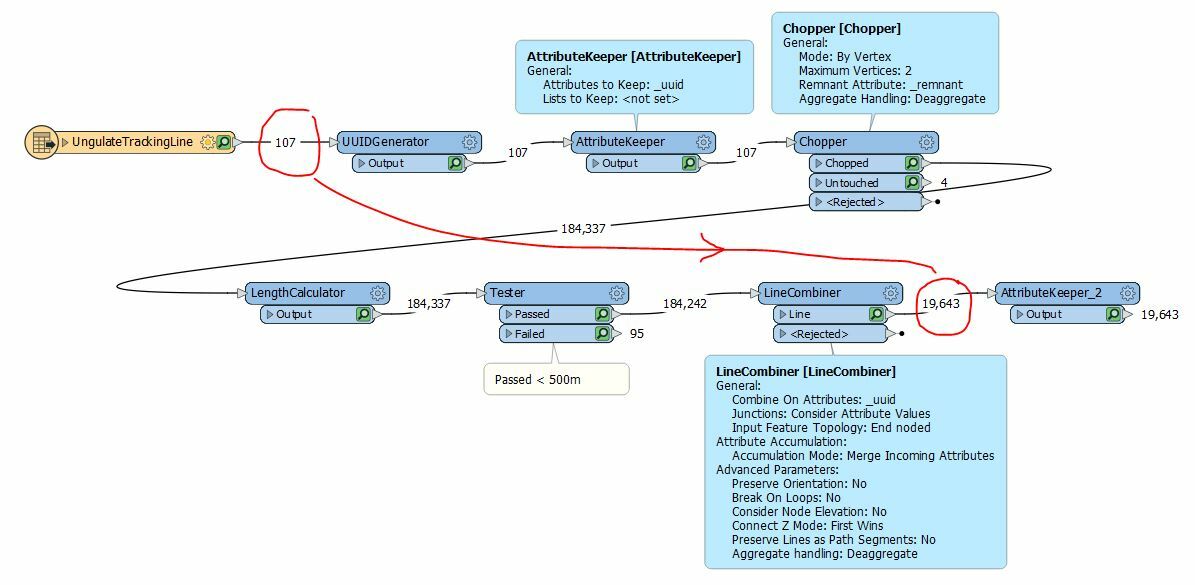
I have a number of GPS tracking records that contain straight line segments i.e. noise arisen from loss of signal. I would like to remove lines > 1 km to improve visualising the data.
The workbench would need to:
- Find straight line segments within each dataset > 1km
- Break/Split the line on the vertex
- Delete the line > 1km
- The lines that have been split at either end can remain as they are i.e. do not need to be merged or joined
Please can someone briefly describe the workflow that I would need to create to achieve this?