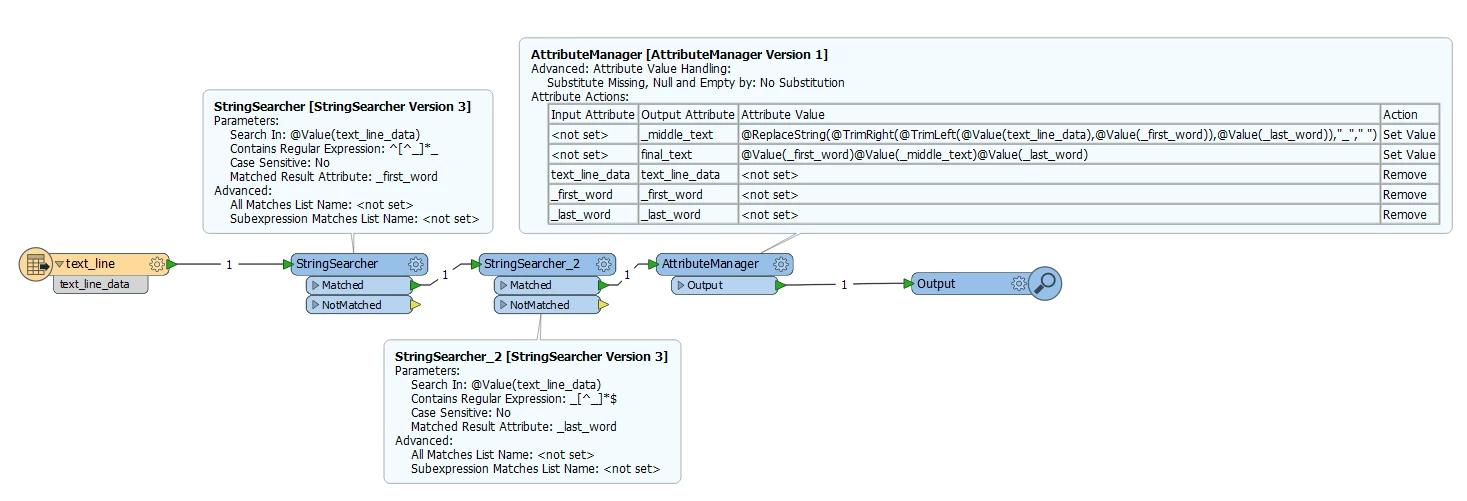
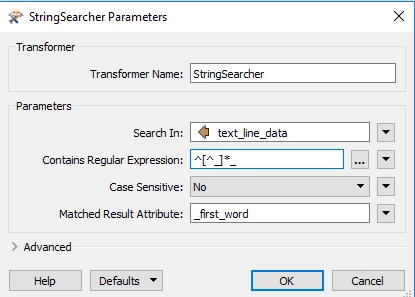
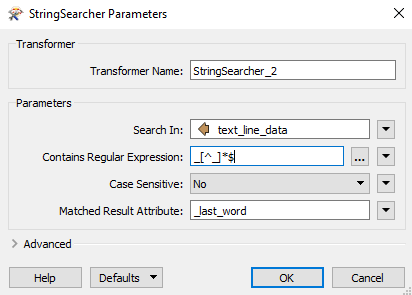
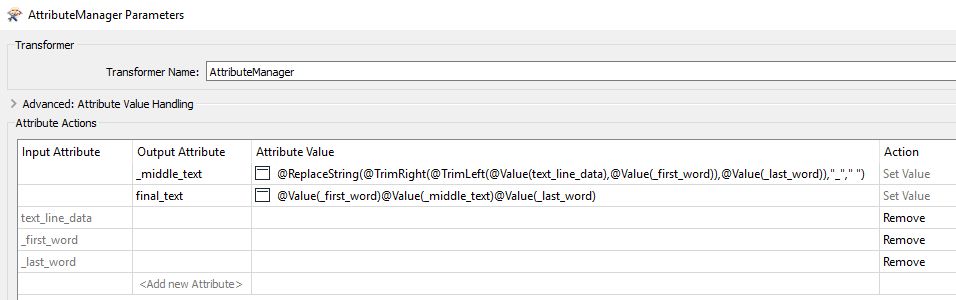
I'd like my regex to replace the middle underscores with a space. I cannot seem to escape the underscore character to use with curly brackets for repetitions.
I have strings with multiple underscores and spaces as word separators. I'd like my result to look like below:
word1_worda wordb wordc wordd_word3
Sample strings look like:
sample1: Autobooster 1_Autobooster Unit_Unit_Autobooster Unit
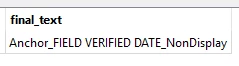
sample2:Anchor_FIELD_VERIFIED_DATE_NonDisplay
With my format these samples should result to:
sample1: Autobooster 1_Autobooster Unit Unit_Autobooster Unit
sample2:Anchor_FIELD VERIFIED DATE_NonDisplay
I used Lookahead and lookbehind and what I'm getting is the middle string with the underscores between word 1 and word 2 and word 2 and word 3 before and after the result. Regex below
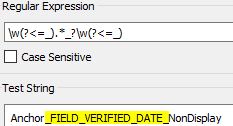
\\w(?<=_).*_?\\w(?<=_)
Test string looks like below
If I were to finish my translation I have to use StringReplacer, StringConcatenator, and then merge them back again.