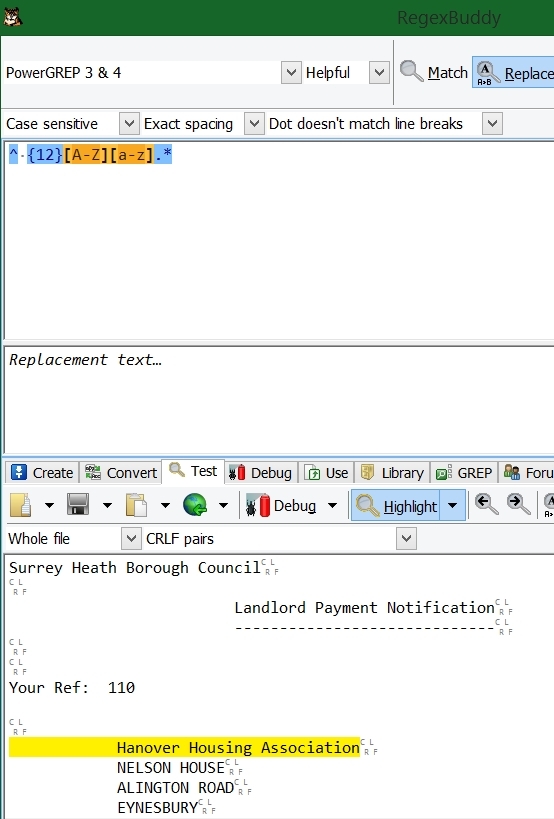
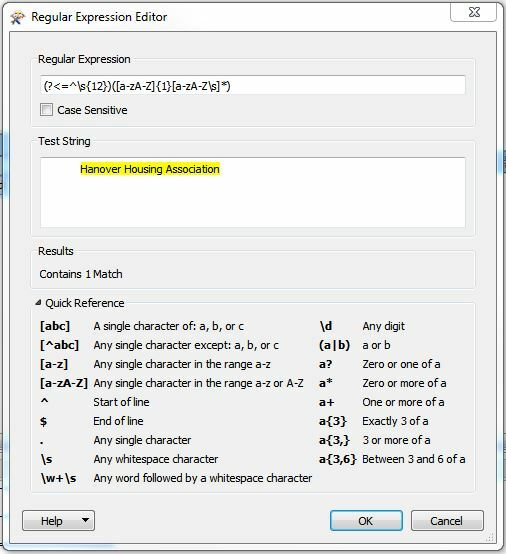
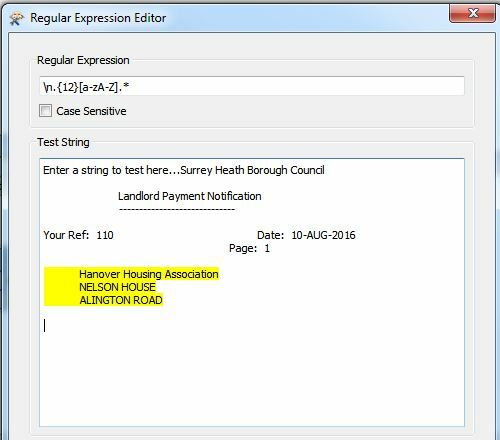
Hi, trying to capture a 'payee' name from text attributes for each feature. The payee name always occurs on the line after 12 spaces. I use some software called Regex Buddy to build and test the regex so I know this works. However, when I plug the regex into StringSearcher in FME and put the same text into the test box, it doesn't work. There's a sample text file attached and the regex I'm using is at the bottom of the file. In this particular file I'm trying to pick up the words Hanover Housing Association. Any ideas anyone??
Thanks
James