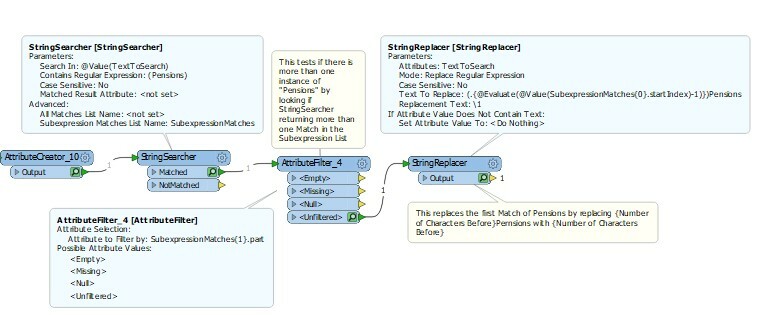
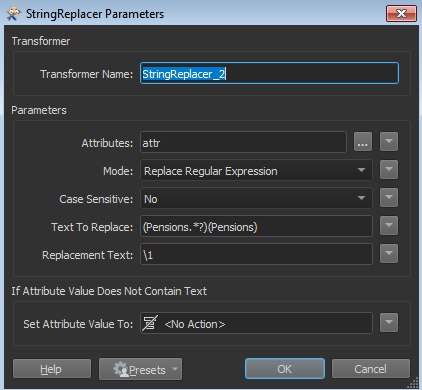
If I had the following string how would I remove a repeated word in this case the word Pensions. So I want to remove the first word that has Pensions but keep the second one.
2006SourcesOfPersonalIncomeTotalResponses06OtherSuperOrAnnuitiesOtherThanNZSuperVeteransOrWarPensionsCURP15YrsAndOver
2006SourcesOfPersonalIncomeTotalResponses06OtherSuperPensionsOrAnnuitiesOtherThanNZSuperVeteransOrWarPensionsCURP15YrsAndOver