Hello all,
I've come up with a difference between Regex editor and workspace run result.
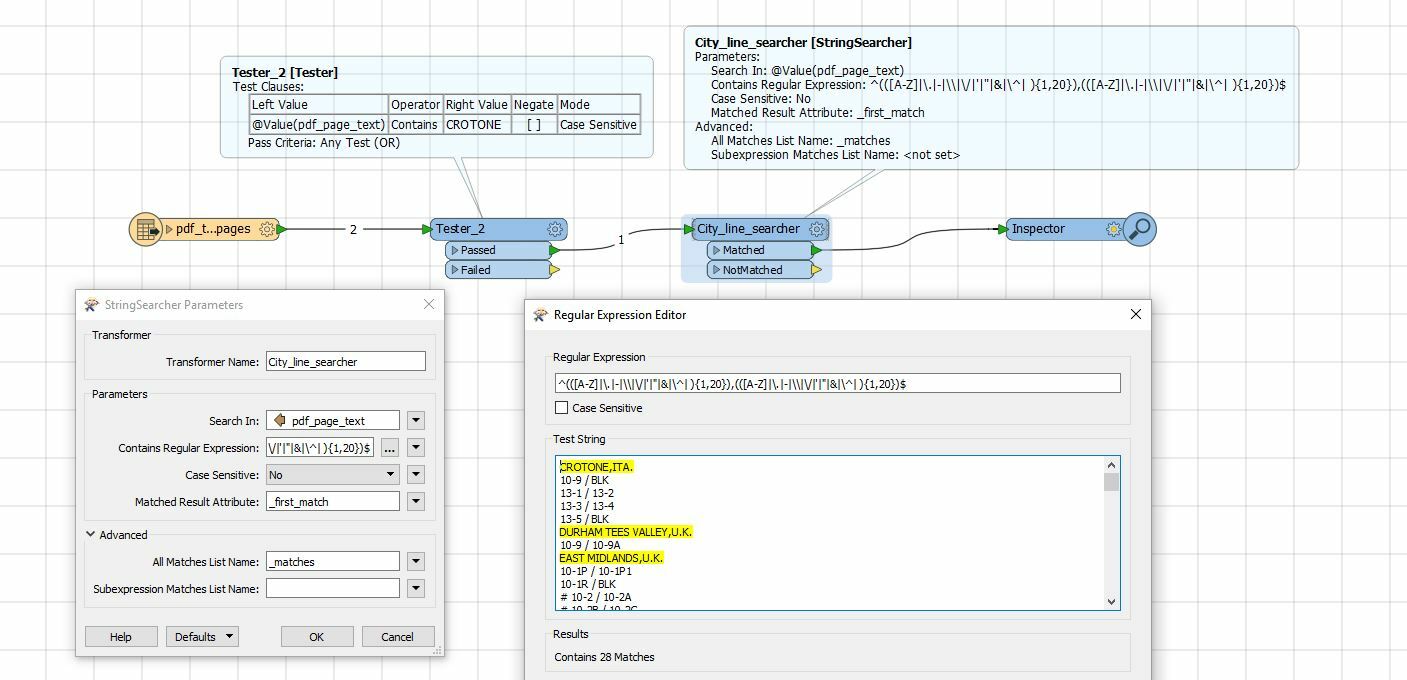
As you can see below I'm expecting to get 28 matches for the feature which has the value written in Test String box in its pdf_page_text attribute. However, the string searcher transformer returns none.
Does anyone know what causes this situation?