
I have lots of csv files that I need to import. Nonetheless, they are arranged in columns and not in lines, i.e. for one csv I have the following :
col0(attribute name), col1(attribute value)
X, 1,
Y, 2,
Z, 3,
In this case, I thus have 3 features with 2 attributes col0 and col1. I want only one feature with 3 attributes X, Y and Z.
I aggregate and create a list, so I have only 1 feature and then tried two techniques :
- RecordBuilder
- AttributeCreator, by specifying for each attribute X, Y, Z the name as @Value(_list{i}.col0) and the value as _list{i}.col1
Displaying the result in the FME Viewer shows the calculation succeeded.
However, the attributes are not created in the workbench so I cannot use them for further process... I tried AttributeExposer but without success.
thanks in advance for your help.
Djekko.



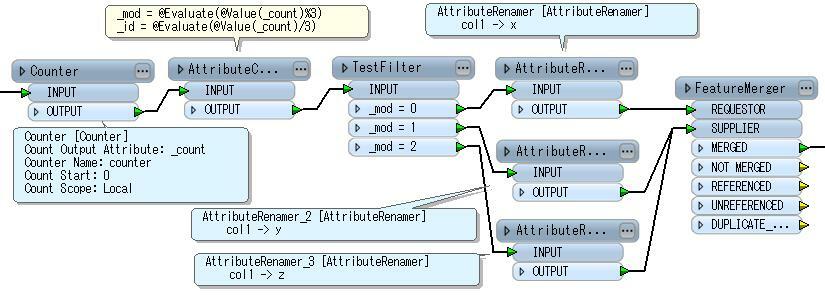 There may be more easier way...
There may be more easier way...



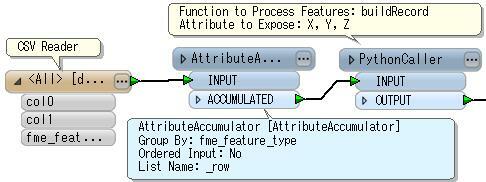 -----
-----
















