
Hi everyone, I'm facing an issue in my workflow: when I process two shapefiles with the same name, the Feature Reader (in Generic mode) interprets them as a single file. This causes an error in my Join. Is there a way to handle this so both shapefiles are read separately?

Solved
Problem in Feature reader
 +5
+5- Contributor
Best answer by francisco_1988
I assume that the two source Shapefile datasets have the same file name (feature type name) but have different schema and you need to read schema feature for each file with the same FeatureReader.
A possible way is:
- create a custom transformer containg a FeatureReader and publish the Group By parameter to make it a group-based transformer,
- in the main workflow, you can set an initiator's attribute that stores source Shapefile path to the Group By parameter of the custom transformer to read schema separately for each dataset, even if the different datasets have an idential file name.
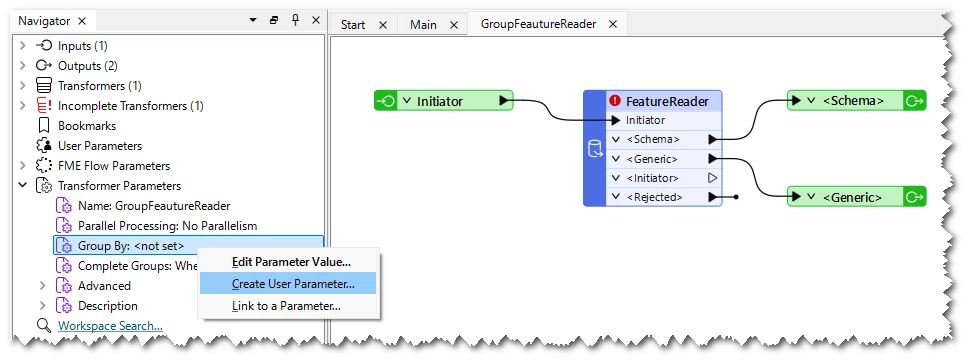
To publish the Group By parameter in a custom transformer definition, right-click on Transformer Parameters/Group By and select "Create User Parameter", on the Navigator of the canvas tab for defining the custom transformer. See also the screenshot below.
Hi Takashi
Thank you!!!
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.


Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.