
")

I have a dataset of around 200,000 records (point geometry with approximately 10 attributes).
I am using the Change detector transformer to update only those records that are updated and to add new records or to mark some as deleted records.
I am using the Feature Writer transformer to write the data into an ESRI Enterprise geodatabase in MS SQL in Azure Cloud. Source data resides in the same geodatabase in Azure Cloud.
!!! FME Server is installed on premise, not in Azure !!!
When initializing the ETL by truncating the destination table and initial loading of the data, the 200,000 records are written in about 7 minutes.
!!! There is an index on the attribute that is used as Primary Key and that attribute is indicated 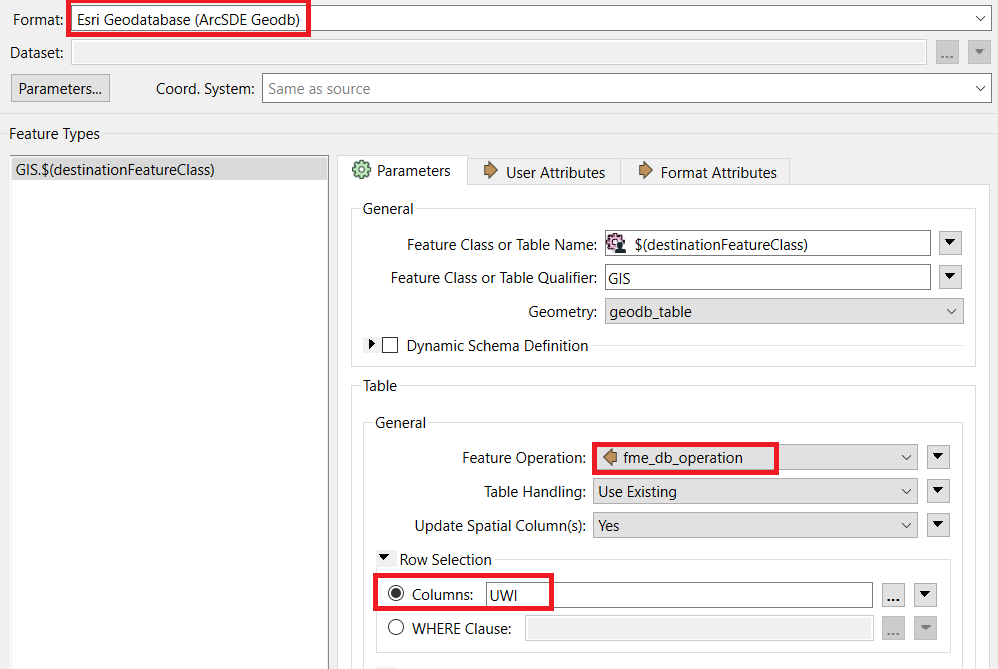 After the initialization, the time to perform the ETL is still low (5-8 minutes) if there are no updates on data, or if there are few updates.
After the initialization, the time to perform the ETL is still low (5-8 minutes) if there are no updates on data, or if there are few updates.
However, if there are many updates (i.e. 100,000 updated records) the time increase dramatically to 4 hours.
Data is written in 3 tables:
- one table storing the attribute that was updated, its initial value and its updated value and a timestamp. This is written quite fast, in a matter of minutes.
- one table storing the destination data. This is written slow: in batches of less than 20 records and 1000 records committed at a time.
- one table storing the history of the records, so data is always added. The same record that is updated is written here so in this table it is possible to find how a certain record looked two months ago. This is written slow: in batches of less than 20 records and 1000 records committed at a time.
1) I noticed that the timestamp of the records that are updated is almost the same. All 100,000 updated records have almost the same timestamp ( 5 seconds range), which differs up o two hours with the time of commit. As other systems are using this timestamp to make an incremental refresh, this "wrong time" written in the database is causing problems to the other systems as they are forced to grab the data only after the entire ETL process is finished and are not able to grab the data during the ETL process. Is there any solution to write the time of commit in an attribute? I am calculating the DateTimeNow(UTC) one step before, not here:
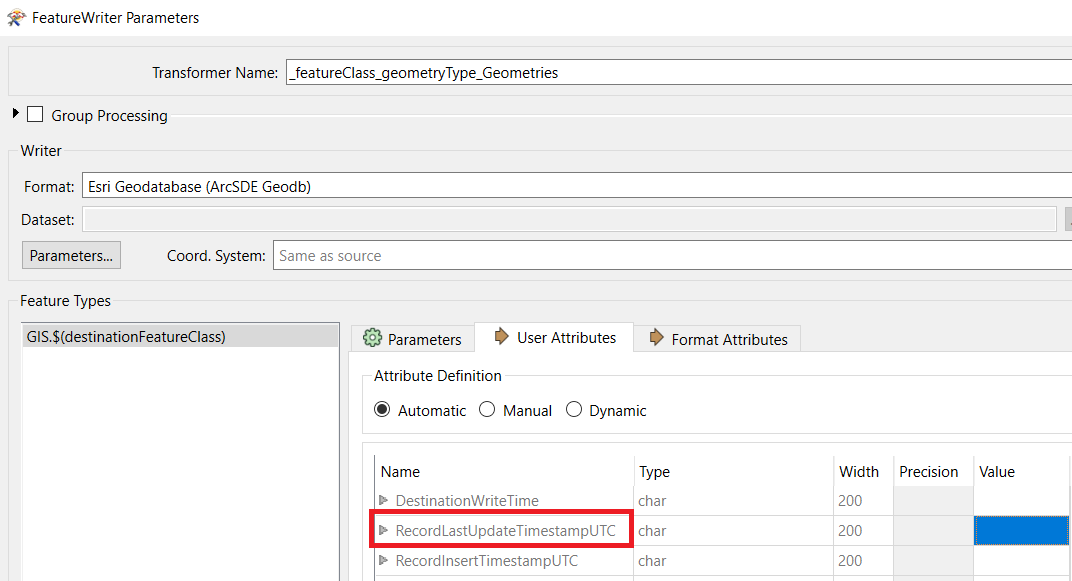
2) Are there any recommendations on how to speed up the process, while keeping the FME Server on premise for the time being?






