
Hi, I am reading text from a pdf using the PDF reader and in the text I see xEF, xBF, xBE - what are these and how do I remove them.
Thank you


 +15
+15Hi, I am reading text from a pdf using the PDF reader and in the text I see xEF, xBF, xBE - what are these and how do I remove them.
Thank you
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.




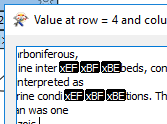 I had some more of a search around and after adding:
I had some more of a search around and after adding: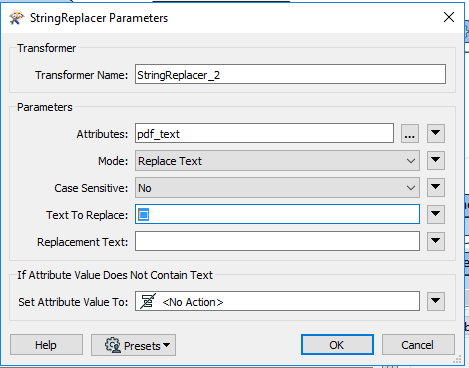 All sorted, thanks
All sorted, thanks