



I have multiple shapefiles in a folder with subfolders. Example Folder "01" has 10 shapefiles, Folder "02" has 15 shapefiles, etc. I was able to create a gdb and load all the features into the gdb but the whole thing is too large. Is it possible to have FME create a new gdb for each subfolder name? What I would want is a new gdb named 01, for the data that was in 01. Another new gdb named 02 for the data that was in 02, etc.
thanks!

")

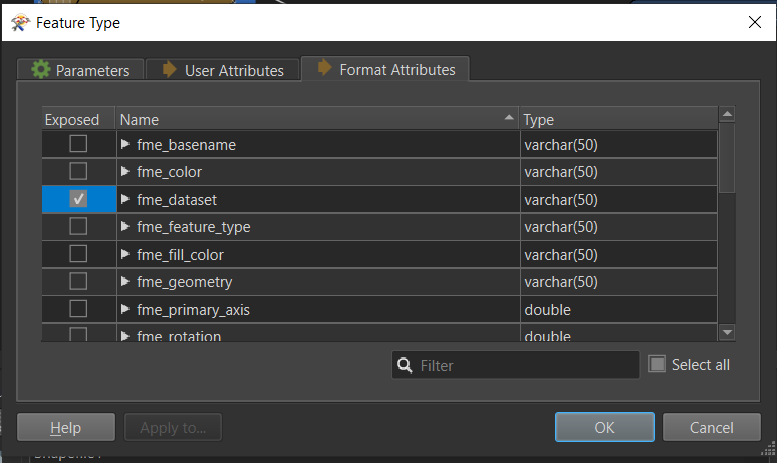 Next, use an AttributeSplitter with \ as the delimiter. This will create a list of each element in the source directory path for each feature. Since it's not guaranteed we know the exact number of folders in the full path, we need to count how many elements are in the directory path. We can use a ListElementCounter for that.
Next, use an AttributeSplitter with \ as the delimiter. This will create a list of each element in the source directory path for each feature. Since it's not guaranteed we know the exact number of folders in the full path, we need to count how many elements are in the directory path. We can use a ListElementCounter for that.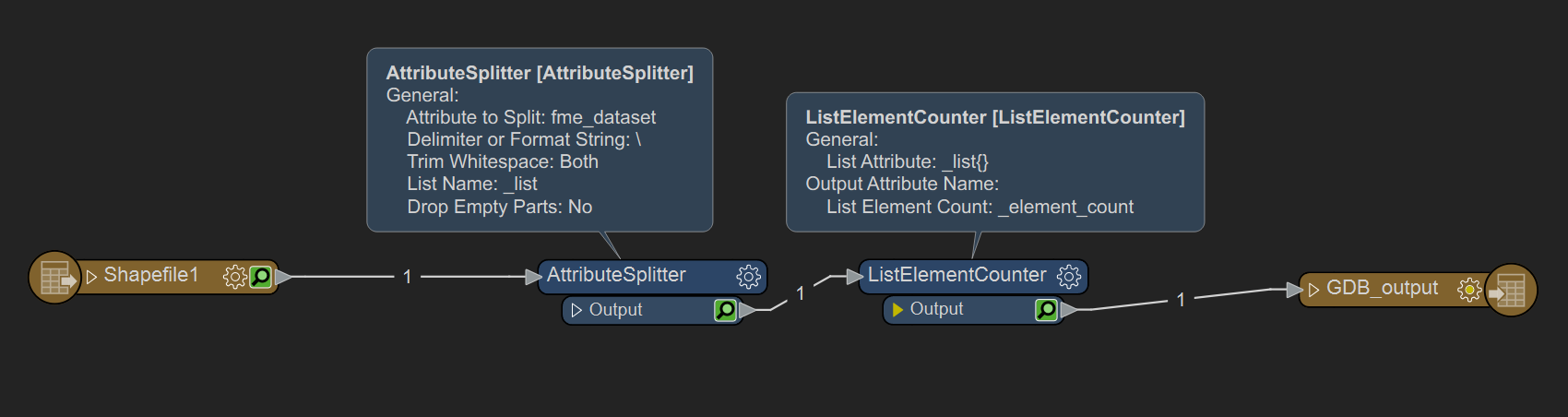 Then on the GDB writer parameters, enable the Fanout parameter and copy this expression in. This should name your gdb after your containing folder.
Then on the GDB writer parameters, enable the Fanout parameter and copy this expression in. This should name your gdb after your containing folder.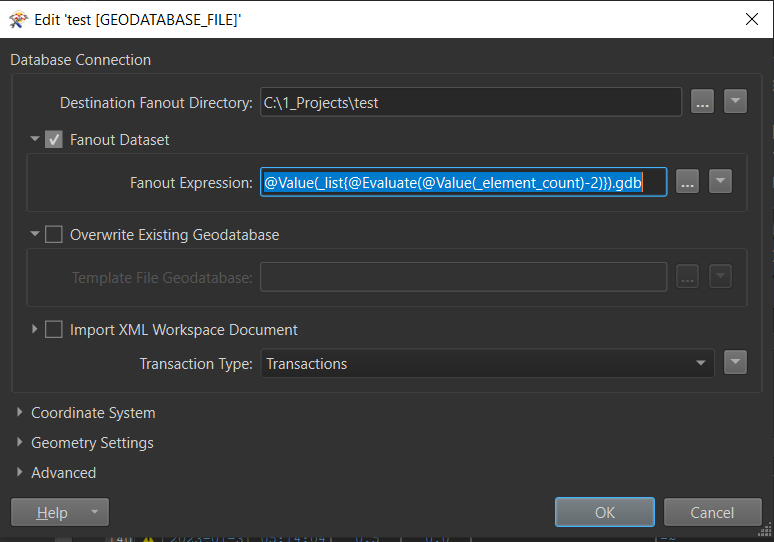 Hope that helps.
Hope that helps.