Hello,
I am having difficulty finding something similar to this in the Knowledge Center so I thought I would ask.
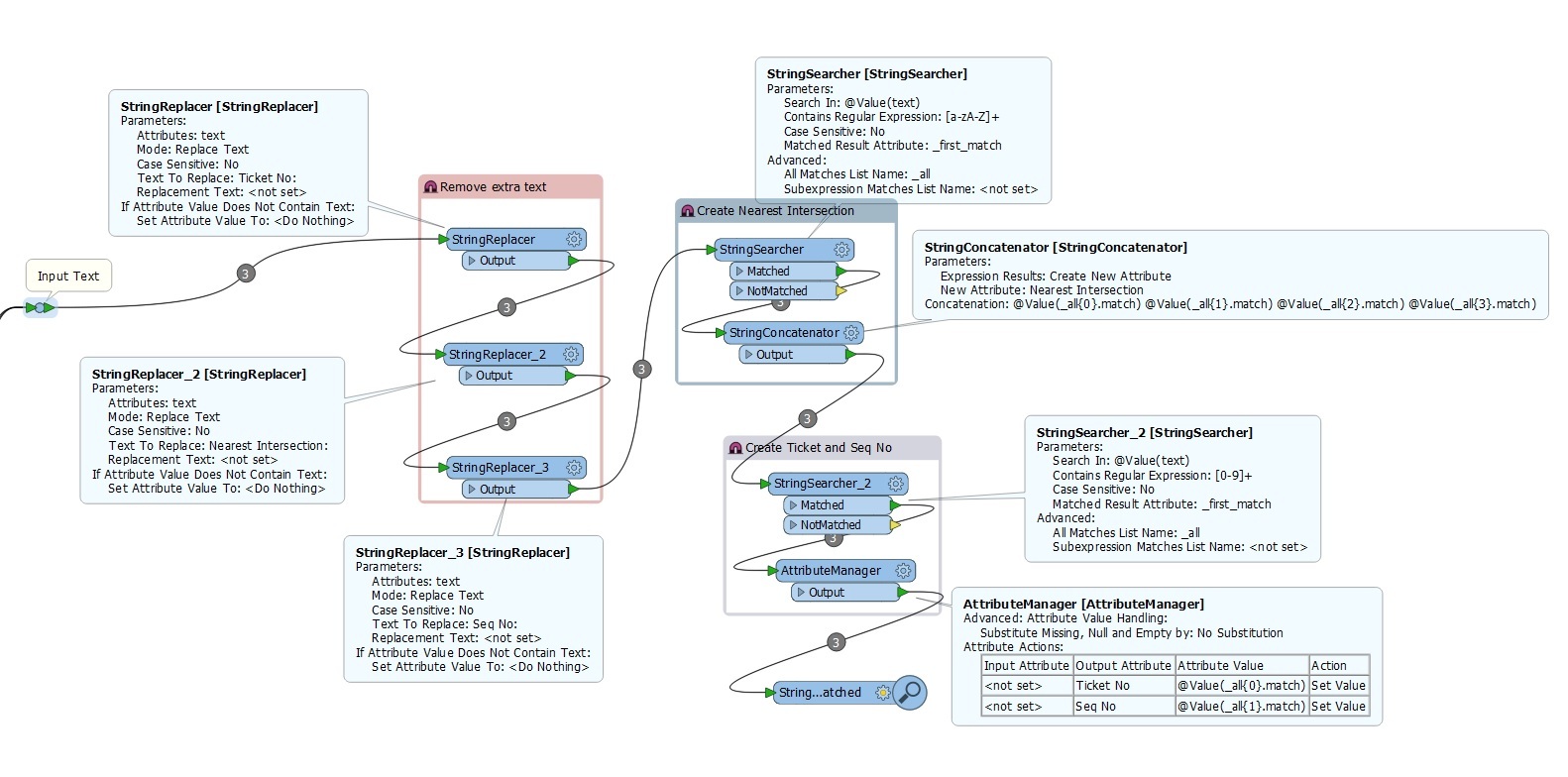
I have an attribute whose value looks like this (it is a full line from a badly formatted text file).
Ticket No: 4653 Nearest Intersection: Chinton Street Seq No: 34
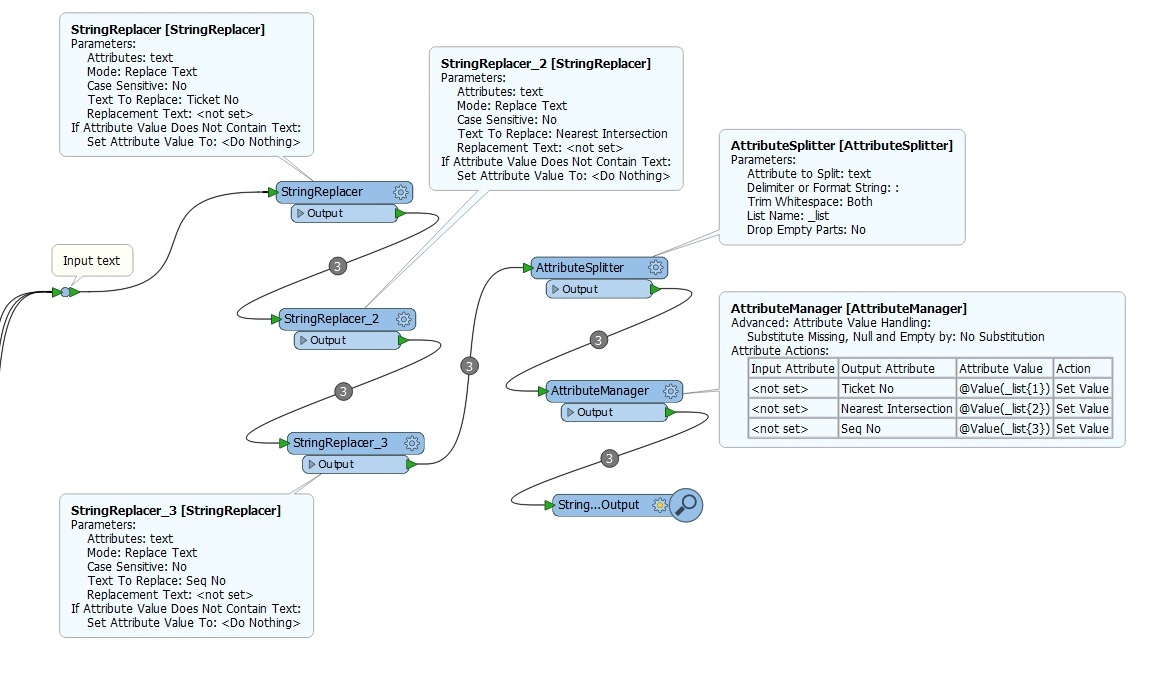
I need them split to an attribute list and subsequent value list
Eg:
Attribute_1 = Ticket No
Value_1 = 4653
Attribute_2: Nearest Intersection
Value_2: Chinton Street
Attribute_3: Seq No
Value_3: 34
It doesn't have to be a "list" as long as I can separate those part of the texts. I am guessing there should be a RegEx way of doing this.
The attribute names "Ticket No", "Nearest Intersection" and "Seq No" will always remain the same with their values changing. I am trying to build a script to always separate them.
Any suggestions? Thank you!
Addition:
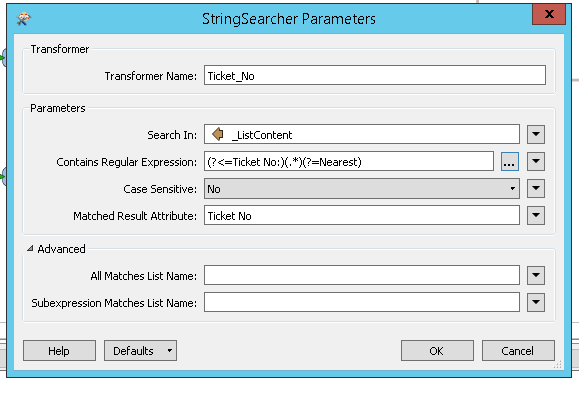
For the first one, if there was a way to extract between 'Ticket No:' and 'Nearest' that would be fine. I can work with the formatting of the value afterwards.
I have 19 lines with the same formatting problems. With 2-3 attributes per line. I am trying to avoid too many transformers per line. If I could possibly use an attribute creator where I create the new attribute and the value would be a the substring between two known attributes on both sides, that would be great.

")