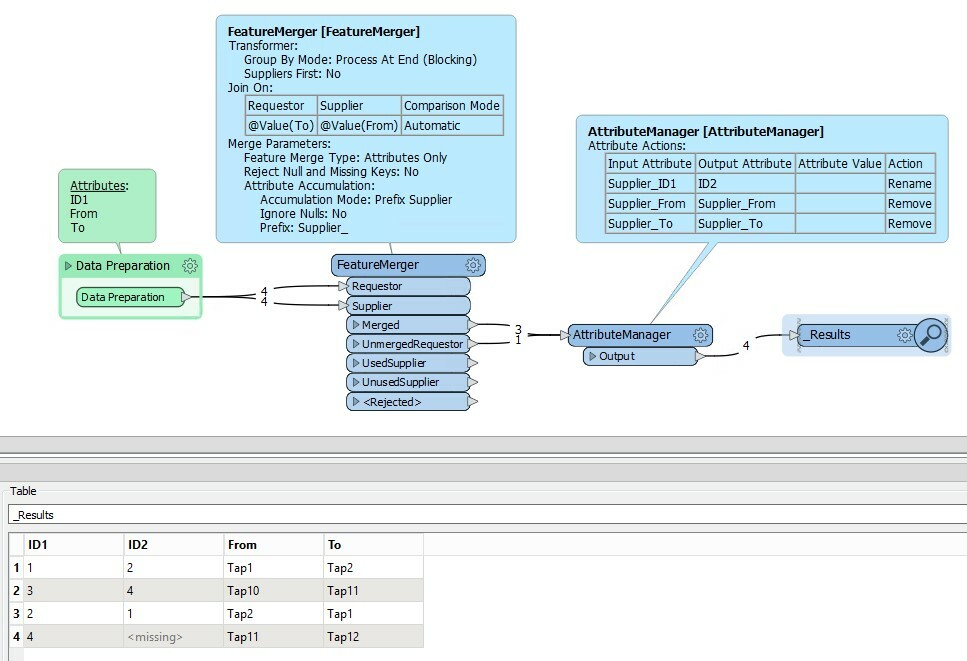
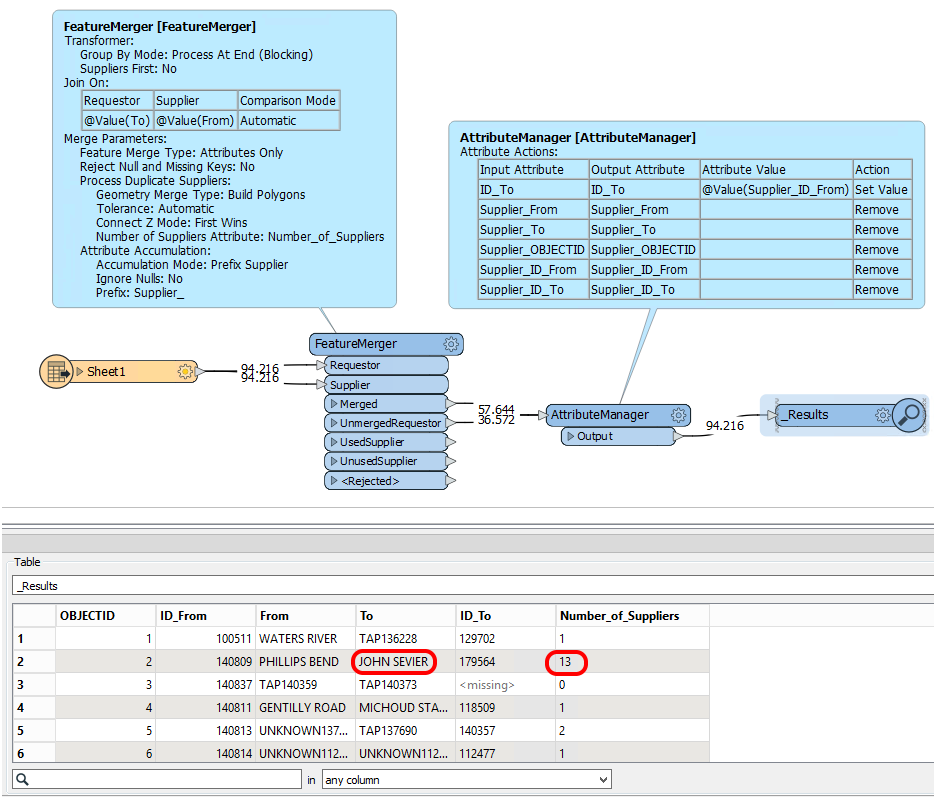
I'm working on data transformation and trying to achieve a task using FME. I have a dataset with two columns(From and To), and I need to match values from one column(From) with values in another column(To).
The third column(ID) corresponds to the value present in col From, so eventually, I have to match the value in col From, find it in another col To, and populate the ID value(in new col ID2) in a new column.
Essentially, I want to find instances where a value from the first column exists in the second column.
Could someone guide me on how to set up an FME workflow to accomplish this? I got an understanding that it can be performed using AttributeCreator using Enable Adjacent Feature Attributes, though not sure if it can, and how!
I appreciate any help or insights you can provide. Thank you in advance for the assistance!
The ID1 values in the below image are IDs of col From. I have to populate ID2 values that refer to To column.