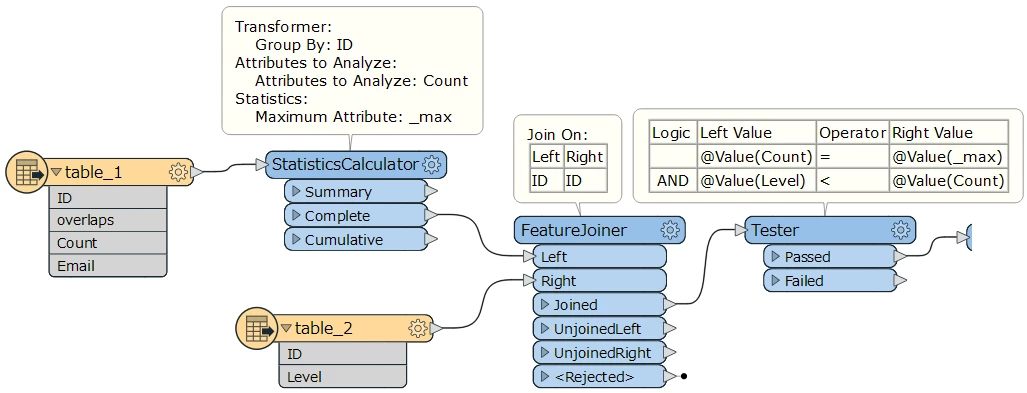
Hi I have the following table after doing a database query
ID overlaps Count Email
0 2 1 PublicOps@sts.com
0 2 1 PrivateOps@sts.com
1 7 3 PublicOps@sts.com
1 7 3 PrivateOps@sts.com
1 7 5 PublicOps@sts.com
1 7 5 PrivateOps@sts.com
2 5 3 PublicOps@sts.com
2 5 5 PrivateOps@sts.com
For each ID, I need to retain the records with maximum count i.e.
for example above, I need to output to be
ID overlaps Count Email
0 2 1 PublicOps@sts.com
0 2 1 PrivateOps@sts.com
1 7 5 PublicOps@sts.com
1 7 5 PrivateOps@sts.com
2 5 5 PrivateOps@sts.com
Following this, I need to join output with table 2 to determine if the count is higher than the level value
for each ID. If it does retain in output, otherwise discard record from table 1
Table 2
--------
ID Level
0 1
1 3
2 3
Hence output expected is:
ID overlaps Count Email
1 7 5 PublicOps@sts.com
1 7 5 PrivateOps@sts.com
2 5 5 PrivateOps@sts.com
I have tried using a sorted a Sorter group by ID/Count/Address , followed by a Sampler
but I am not getting the desired output
Any suggestions?