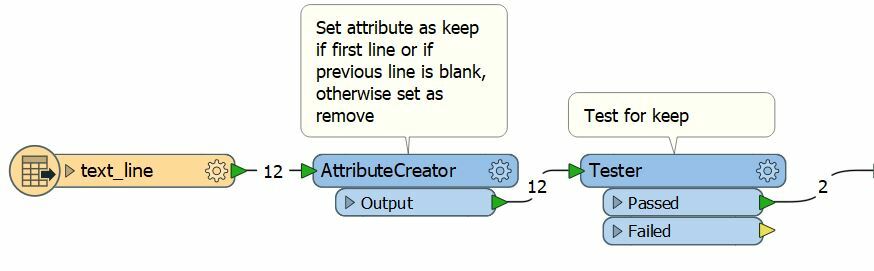
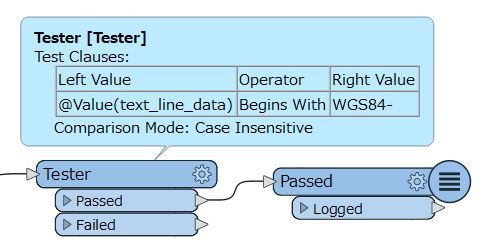
Hi @takashi, do you have any ideas on how I would isoloate this first line of text in each 'cluster' of text? I have about 3000 to isolate.....The cluster formats are all the same but the first line of text varies in length.
This information is stored in a text file at the moment and each clusters is separated by 1 character return.
WGS84-YORK_LANDING-CZAC
DESC_NM WGS84 YORK_LANDING CZAC
DT_NAME WGS84
PROJ LM
UNIT INCH
WGS84-CASTLEGAR_-CCT3
DESC_NM WGS84 CASTLEGAR_ CCT3
DT_NAME WGS84
PROJ LM
UNIT INCH