")

Hi,
I’m having trouble with AmazonBedrockConnector and I believe it’s an error with how the transformer has been authored.
The issue is that the transformer processes and outputs the square of the number of input records. If I input 13 records, it will process 169 (to AWS Bedrock!), and then output them. If I input 313 records, it will attempt to process and return 97,969 records (I’ve found this out the hard way).
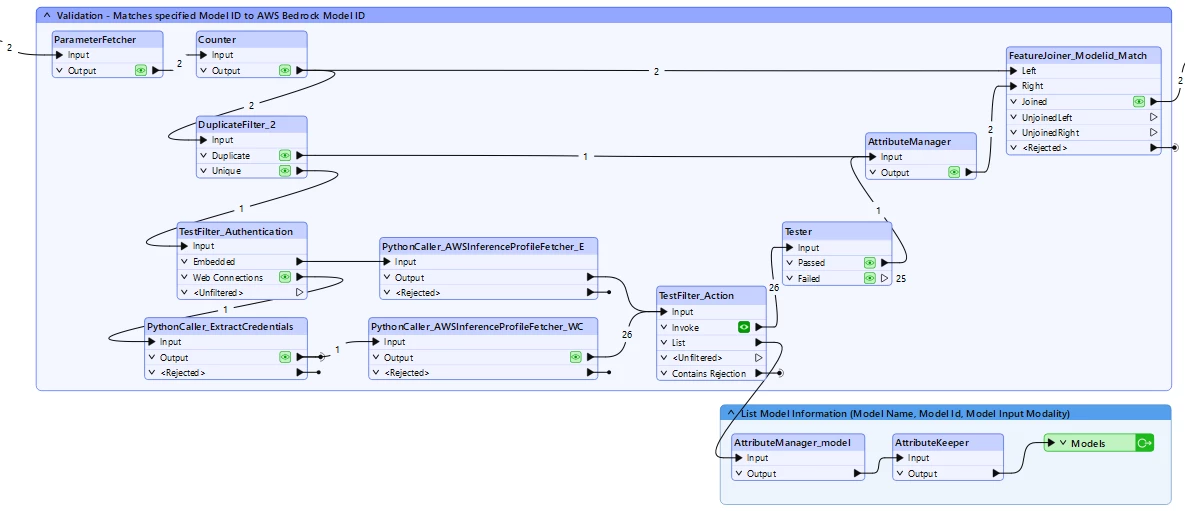
By embedding the transformer and then editing it, I was able to view the flow of information from a source workspace. The issue seems to be in the calling and validation of AWS Inference Profiles, in that they are checked to be active, and then joined back to the original input records (obviously to allow error checking and rejection). As downloaded, the transformer looks like this:
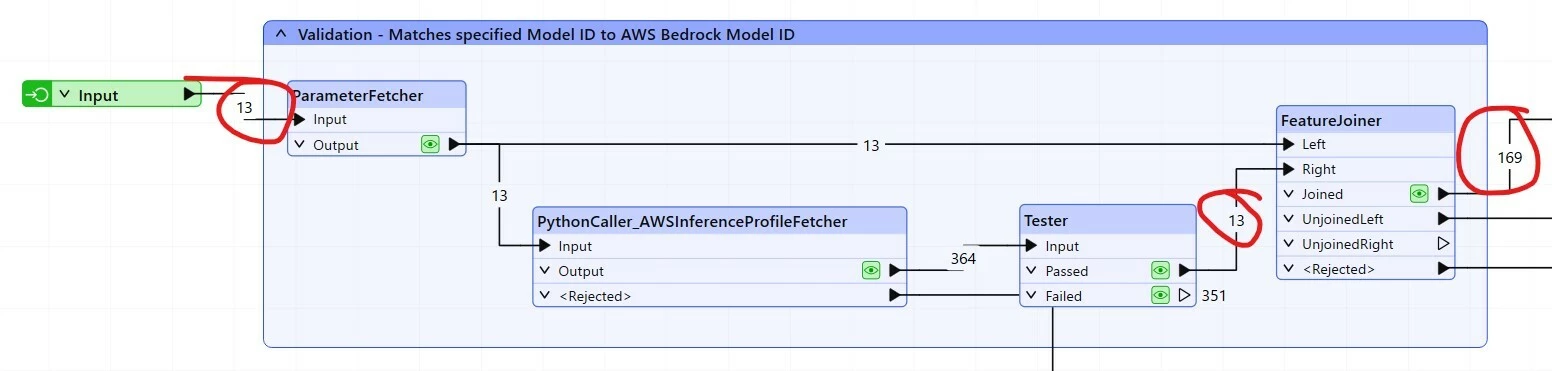
Note that the 13 input records are joined back against each other to create 169 records that are ulimately sent to the Bedrock API. I can see no valid reason to keep all of the original records out of the Tester, simply to validate the status of the inference profile, which can be done once. I’m happy to be shown why that might be needed though.
To fix what I believe is an error, I introduced an aggregator after the Tester to validate the active status of the profileID, creating only 1 record for my selected profile that is then joined upon by the rest of the input records.
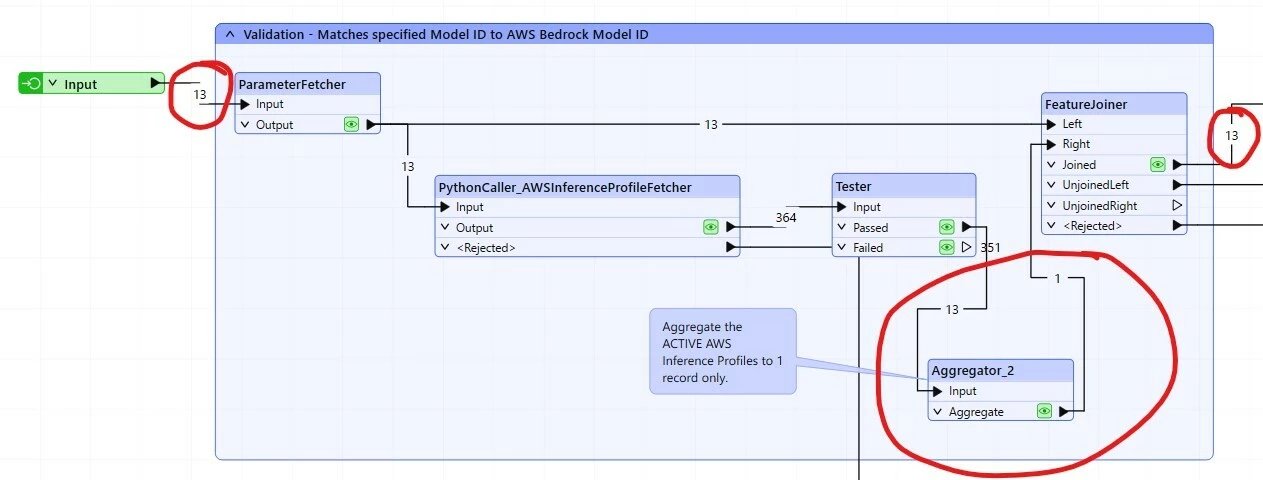
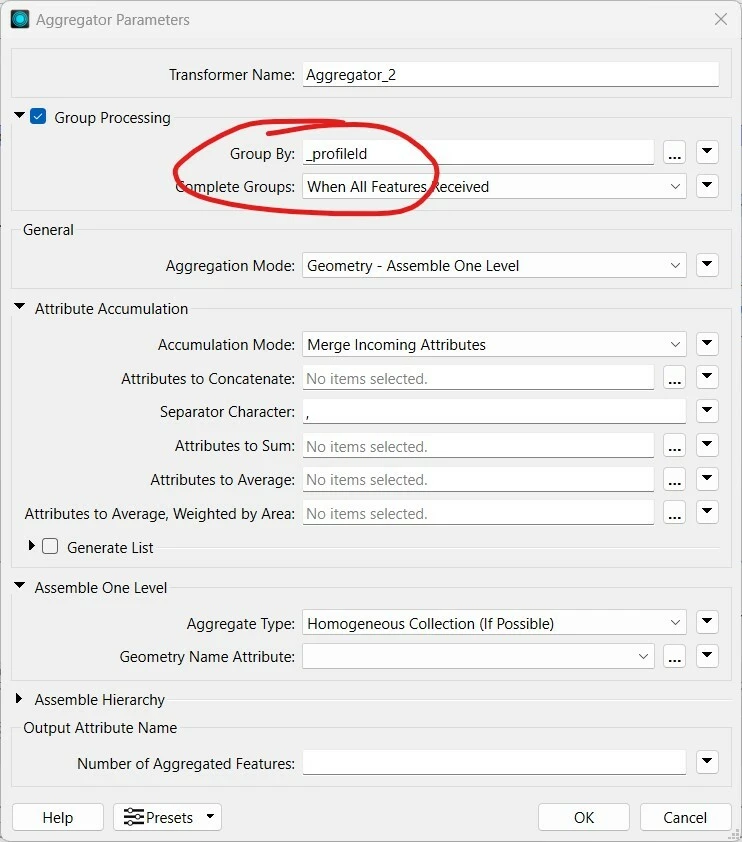
In this way, the active profile is validated but only the intended number of input records gets sent to Bedrock.
Finally, to allow the FeatureJoiner to operate correctly, I also ungrouped by Prompt.
If I’m wrong about this, please let me know and I’ll delete the question! If it’s valid though, I think the transformer needs to be updated.
Thanks,
Leon.