To ensure our database's data integrity, which is periodically enriched with measurement data governed by users, we use FME to create data validation reports in Excel. With these reports, users can correct their data iteratively.
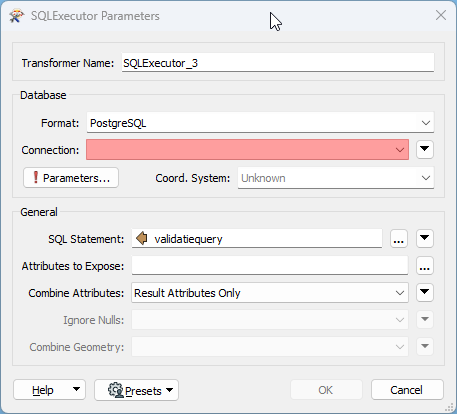
To make this work, we use SQL statements stored as attributes in a table. Depending on the report to be generated, SQL statements are fed into a SQLExecutor transformer as attributes. At the time of writing, we employ close to 500 validation queries, each with their own set of columns as well as amount of columns. The picture below shows how the queries are inserted into the SQLExecutor as an attribute.
This is then routed to a dynamic Excel writer by using the SchemaSetter custom transformer. The Excel report is generated as expected, except for the column order, which is sorted alphabetically instead of the order specified by the (dynamic) SQL queries.
Is there a way to preserve the column order specified by the SQL queries instead of having them sorted alphabetically?
Our current workaround is to manually add a prefix to the attributes in the SQL statements themselves, but this is not a desired solution.
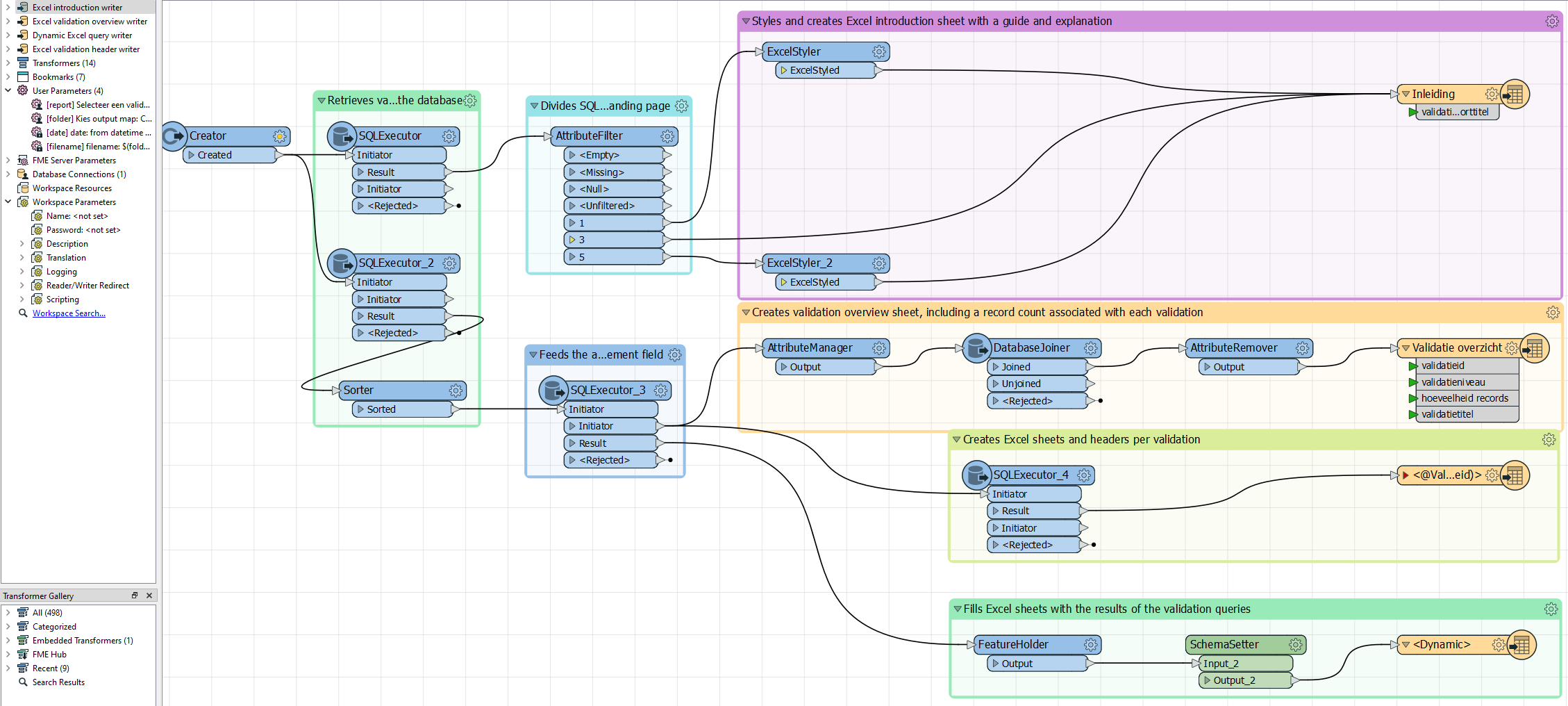
The full workspace looks like this:
Best answer by peter_r
peter_r wrote:
Thanks for your suggestion, this could work nicely for about half of all SQL queries. However, we house close to 500 data validation and overview queries, each having a different selection of columns as well as different amounts of columns. I've updated the text in the question to make this more clear.
In addition, if a data validation query does not result in any records, it is omitted from the Excel report - except for the overview sheet, where the validation is listed as having 0 records. To my knowledge, a template file would still show Excel sheets for empty validations.
I managed to solve the problem by first updating to the latest version of FME (2023.1.1.1).
For starters, this fixed the error I kept encountering with the SchemaScanner, i.e.:
SchemaScanner (SchemaScannerFactory): Factory clause has invalid parameters. Expected syntax is TEMPLATE_SCHEMA <attr_pattern>
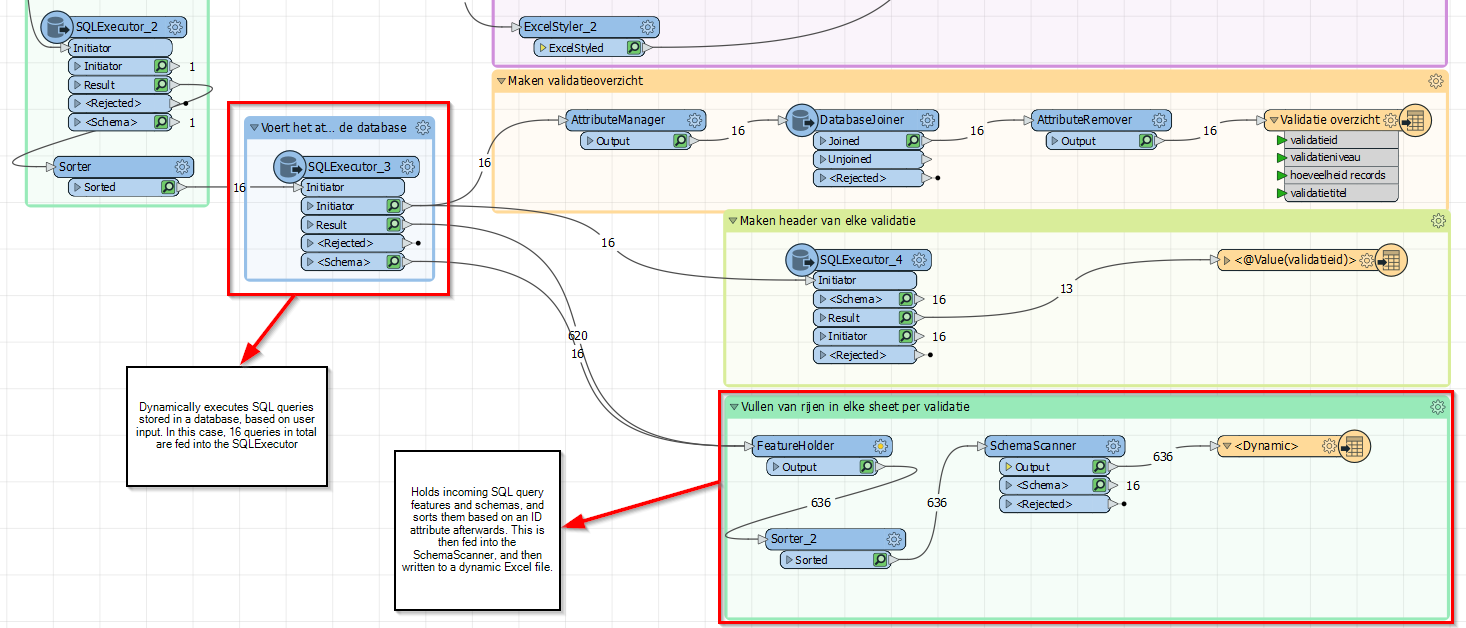
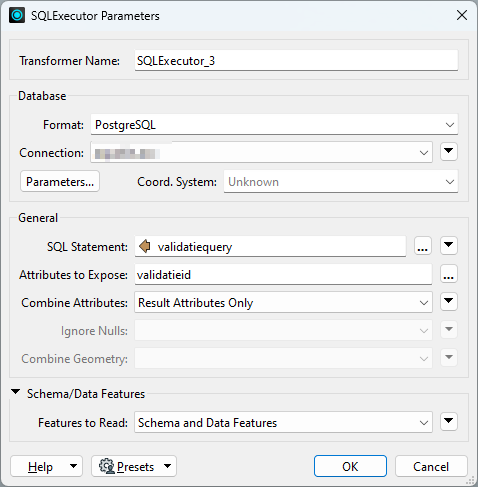
Secondly, the update enabled a <schema> output from the SQLExecutor transformer which I routed together with the results output into a SchemaScanner after a sorting step, as can be seen in the attached image. The SQLExecutor parameters are included as well.
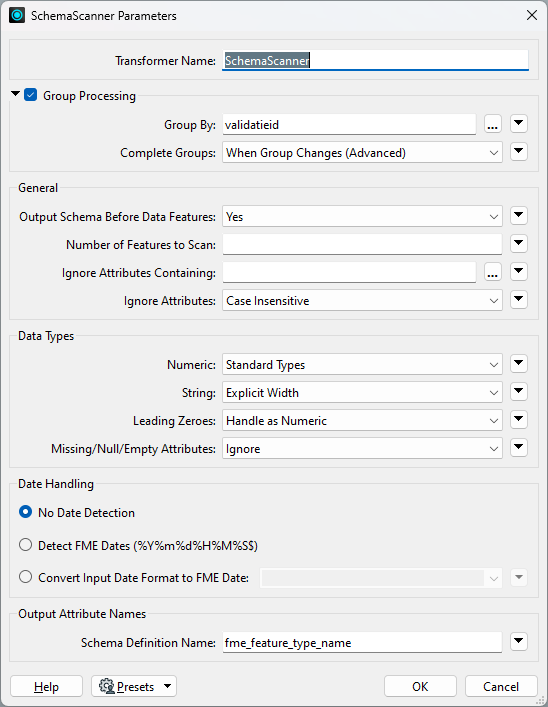
In the SchemaScanner, I set Output Schema Before Data Features to 'yes', and turned on group processing based on an exposed query ID attribute. SchemaScanner parameters can be seen here:
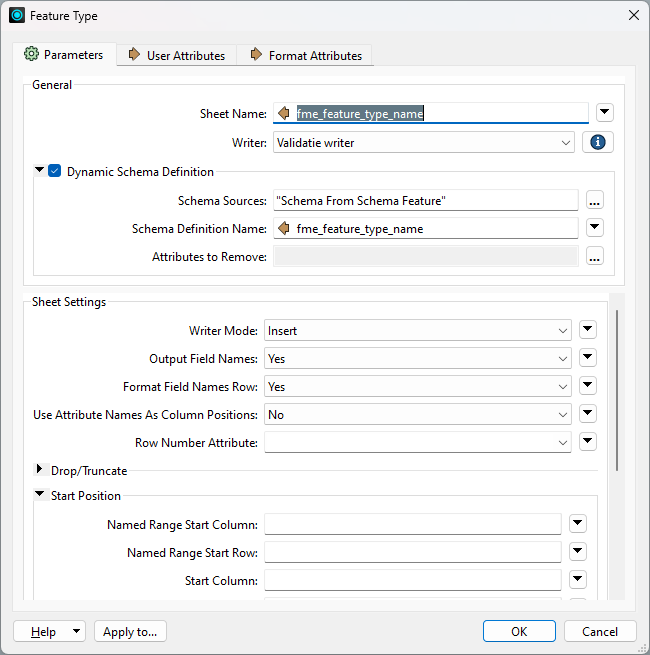
In the dynamic Excel writer I then set Schema Sources to "Schema From Schema Feature" and as the Schema Definition Name I used the fme_feature_type_name attribute exposed by the SchemaScanner. In my case, the fme_feature_type_name is identical to the value I wanted the sheet names to be.
Thanks for the help and ideas, I've put some related links that helped me solve this problem here:
As a workaround, could you use template files to control the column order in your excel files?
Thanks for your suggestion, this could work nicely for about half of all SQL queries. However, we house close to 500 data validation and overview queries, each having a different selection of columns as well as different amounts of columns. I've updated the text in the question to make this more clear.
In addition, if a data validation query does not result in any records, it is omitted from the Excel report - except for the overview sheet, where the validation is listed as having 0 records. To my knowledge, a template file would still show Excel sheets for empty validations.
Thanks for your suggestion, this could work nicely for about half of all SQL queries. However, we house close to 500 data validation and overview queries, each having a different selection of columns as well as different amounts of columns. I've updated the text in the question to make this more clear.
In addition, if a data validation query does not result in any records, it is omitted from the Excel report - except for the overview sheet, where the validation is listed as having 0 records. To my knowledge, a template file would still show Excel sheets for empty validations.
*To my knowledge, a template file would still show Excel sheets for empty validations.*
I think this might be a new option, i've not had reason to try it yet
I think your only other option is to somehow use the sql queries to manually create the schemas with the columns in the order you want. Not sure how complex your sql queries are as to whether that is remotely feasible.
As an aside, what version of FME are you working with? The SchemaScanner replaces the SchemaSetter from I think 2021 onwards
Thanks for your suggestion, this could work nicely for about half of all SQL queries. However, we house close to 500 data validation and overview queries, each having a different selection of columns as well as different amounts of columns. I've updated the text in the question to make this more clear.
In addition, if a data validation query does not result in any records, it is omitted from the Excel report - except for the overview sheet, where the validation is listed as having 0 records. To my knowledge, a template file would still show Excel sheets for empty validations.
Thanks for your ideas! I am fairly new to FME still and have a lot to learn.
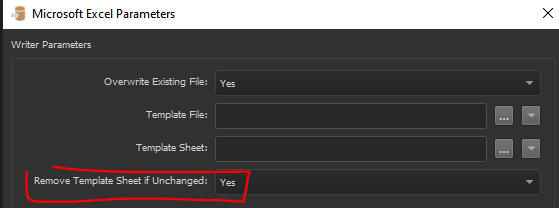
First off, I'm using an older version of FME (2021.2). I'll update my FME client to the latest version first and then continue with trying your template idea with the Remove Template Sheet if Unchanged setting in the Excel writer. I'll also simultaneously try obtaining the schemas from the SQL queries themselves, and use the SchemaScanner transformer instead of the SchemaSetter custom transformer.
I will report back here in this comment chain with my findings.
Thanks for your suggestion, this could work nicely for about half of all SQL queries. However, we house close to 500 data validation and overview queries, each having a different selection of columns as well as different amounts of columns. I've updated the text in the question to make this more clear.
In addition, if a data validation query does not result in any records, it is omitted from the Excel report - except for the overview sheet, where the validation is listed as having 0 records. To my knowledge, a template file would still show Excel sheets for empty validations.
I managed to solve the problem by first updating to the latest version of FME (2023.1.1.1).
For starters, this fixed the error I kept encountering with the SchemaScanner, i.e.:
SchemaScanner (SchemaScannerFactory): Factory clause has invalid parameters. Expected syntax is TEMPLATE_SCHEMA <attr_pattern>
Secondly, the update enabled a <schema> output from the SQLExecutor transformer which I routed together with the results output into a SchemaScanner after a sorting step, as can be seen in the attached image. The SQLExecutor parameters are included as well.
In the SchemaScanner, I set Output Schema Before Data Features to 'yes', and turned on group processing based on an exposed query ID attribute. SchemaScanner parameters can be seen here:
In the dynamic Excel writer I then set Schema Sources to "Schema From Schema Feature" and as the Schema Definition Name I used the fme_feature_type_name attribute exposed by the SchemaScanner. In my case, the fme_feature_type_name is identical to the value I wanted the sheet names to be.
Thanks for the help and ideas, I've put some related links that helped me solve this problem here:
We use 3 different kinds of cookies. You can choose which cookies you want to accept. We need basic cookies to make this site work, therefore these are the minimum you can select. Learn more about our cookies.







 I think your only other option is to somehow use the sql queries to manually create the schemas with the columns in the order you want. Not sure how complex your sql queries are as to whether that is remotely feasible.
I think your only other option is to somehow use the sql queries to manually create the schemas with the columns in the order you want. Not sure how complex your sql queries are as to whether that is remotely feasible.












