I'm wondering if anyone would bo so kind as to help me with a little issue I'm having...
I have a dynamic ESRI shapefile source folder, with multiple shapefiles within.
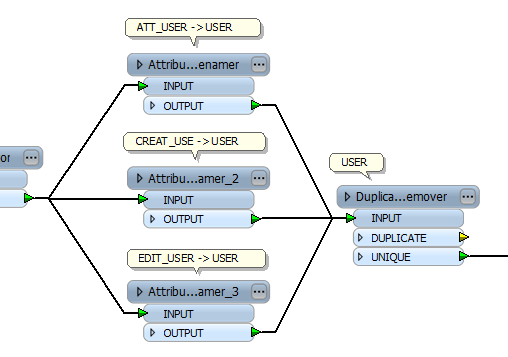
All of these features have 1 thing in common, namely that they all contain the following attributes:
CREAT_USER
EDIT_USER
ATT_USER
Now these attributes all contain actual names, like Jeff, Pete, etc...
Ok, so lets say In CREAT_USE has multiple entries (inside multiple features, as this is a folder I point to and all shapes within get read) of the following names:
-Pete
-Jeff
EDIT_USER has:
-Jeff
-Susan
ATT_USER has:
-Susan
-Pete
-Rick
I want a summarization of all the possible values contained within all the source shape files. I don't care for the counts that these entries occur, so I simply want all the "possible unique values", filtering out all duplicates. Example output:
-Pete
-Jeff
-Susan
-Rick
Please feel free to ask more questions if this doesnt make sense.
Keep in mind that even though CREAT_USER, EDIT_USER, and ATT_USER will always remain like that, the values (aka the names) could differ each time, depending on what source data it's run on.
Thanks in advance,
Robbie