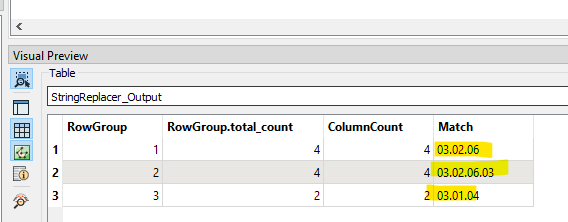
I am trying to match attributes and write the matching part of the substrings into a new attribute. The following table explains it best:
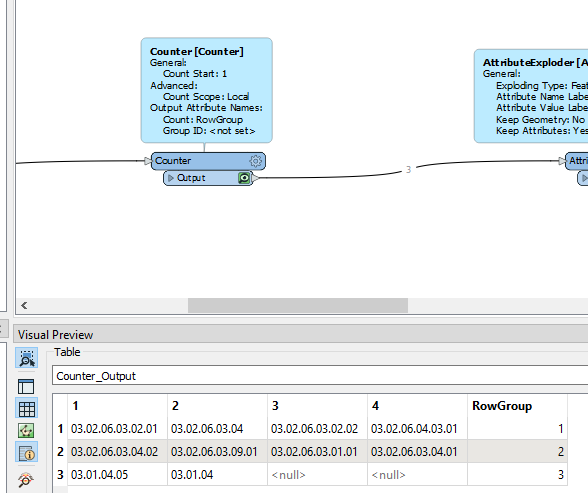
1
2
3
4
match
03.02.06.03.02.01
03.02.06.03.04
03.02.06.03.02.02
03.02.06.04.03.01
03.02.06
03.02.06.03.04.02
03.02.06.03.09.01
03.02.06.03.01.01
03.02.06.03.04.01
03.02.06.03
03.01.04.05
03.01.04
03.01.04
Note that the fields may also be empty and should then be ignored and not all strings are the same lenght. I am also trying to match from the start of the string only.
The only idea that came to me so far is to create lists for each attribute using the attribute splitter and then use conditionals to compare each two-digit part seperately, create each sequence and then string them back together. Maybe there is an easier way?
Best reagrds.
Best answer by bwn
AttributeSplitter will work but have to think more laterally about the logic 😉 Channelling our inner @takashi who had excellent tips of transforming non-spatial coordinates into spatial coordinates to find complex intersections using spatial intersection transformers, we can conceptualise the data is actually Linestrings.
Eg. “03.02.06.03.02.01” is actually a line with 6 vertices where:
X = Substring Position Number
Y = Substring Numerical Value
Becomes:
LINESTRING(0 3, 1 2, 2 6, 3 3, 4 2, 5 1)
What we can do then, is transform the substring number sequences into Line Geometries with vertex coordinates corresponding to each Substring “Point”, and then use LineOnLineOverlayer to tell you which “partial lines” overlap, which will be just the part of the total string that contains overlapping substrings, per Row Group.
Sample data, with Row Group Number added with a Counter:
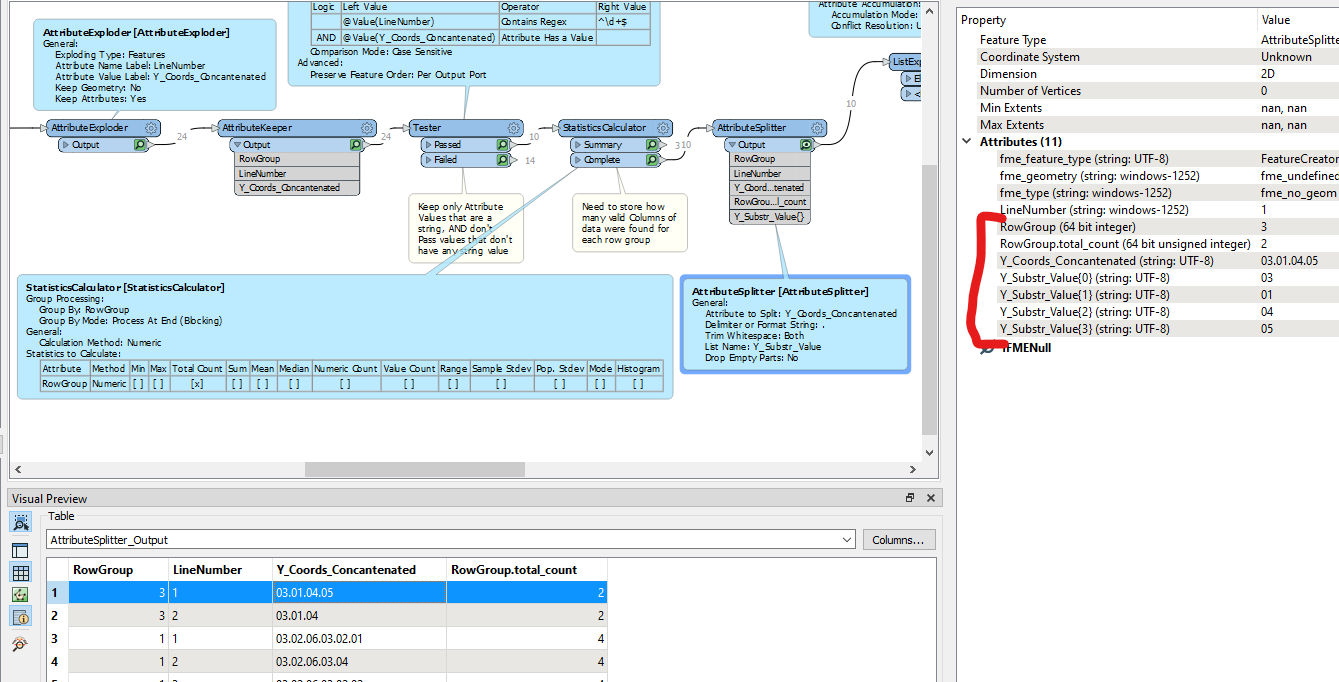
Flowing through to AttributeSplitter, this now gives the Y coordinates of the Line vertices, being the Substring numeric values
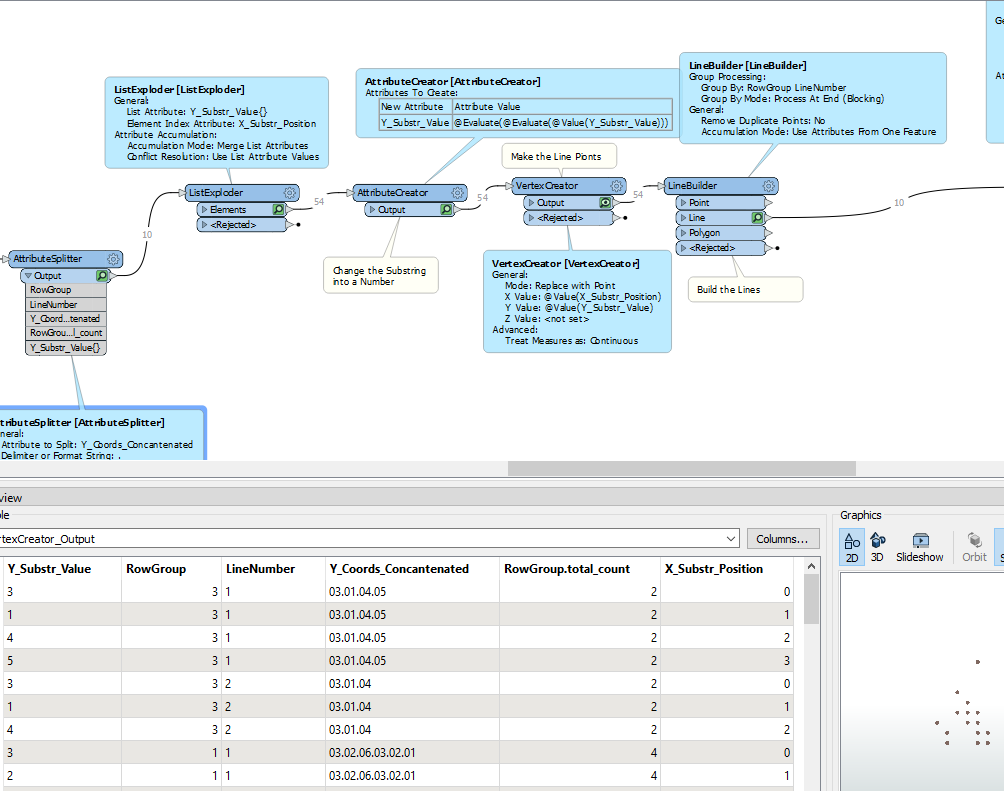
Build Line Geometries out of this data that are going to find the coincident line parts with LineOnLineOverlayer
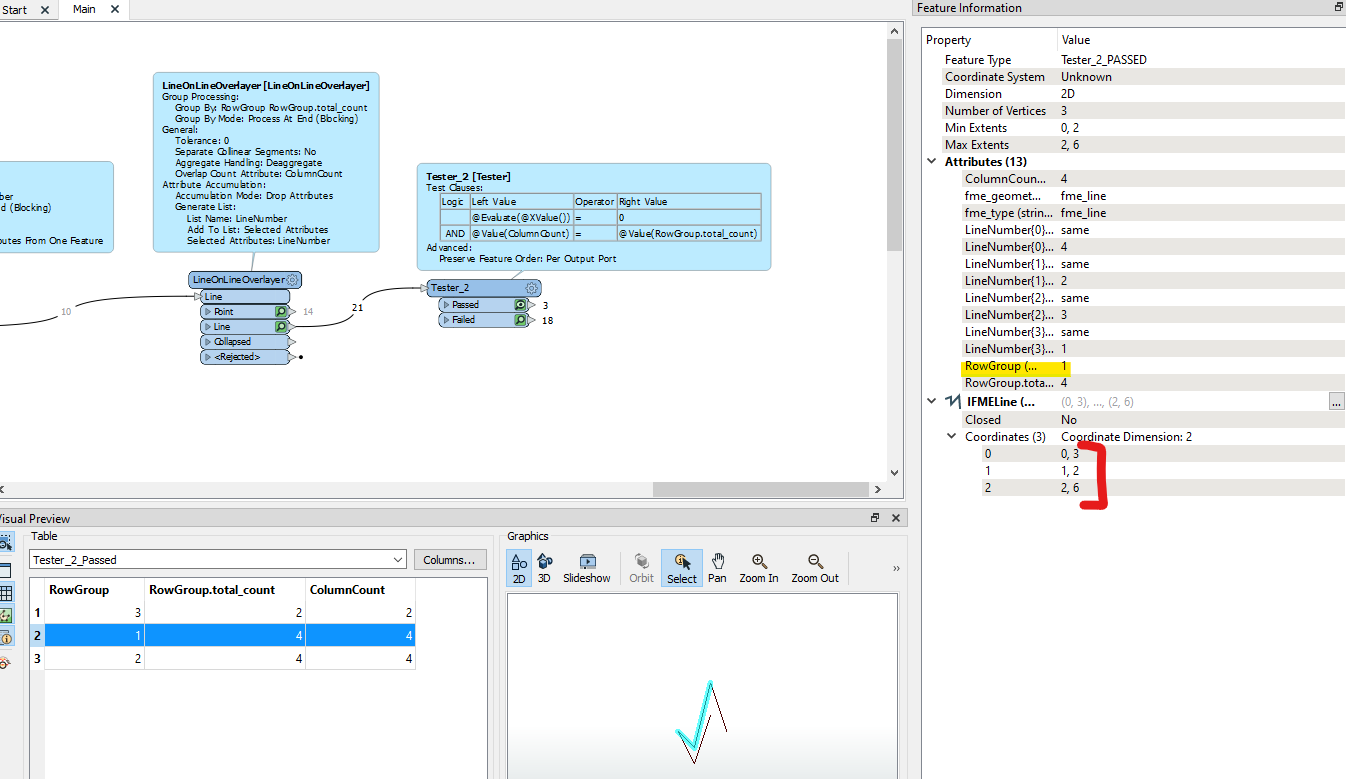
Now post-process and using Tester just select the sub-line that absolutely contains a Substring in the 0 X coordinate position (ie. This is a line that does contain the very first substring value) within the Total String AND make sure the Overlap Count that contains the same Count of Valid Columns. ie. We need to ensure this line overlaps 4 times for 4 valid columns. If it only overlapped 3 times then this was one column that did not have the same starting substring value and there would be no common substring then for that row.
The output of the Tester below will be the longest sequence of “points” that being from the starting substring, and matches across all of the columns
Can see for Row 1 in the original table, the longest matching sequence output in the LineOnLineOverlayer List is “03, 02, 06” . I haven’t shown the extra ListExploder, AttributeCreator to put the leading “0” back onto the number and Aggregator to put them back into concantentated, comma-delimited form.
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
I’m not sure there’s an elegant way to do it in FME. A python method is probably quite straightforward and probably is less lines of code than FME transformers
AttributeSplitter will work but have to think more laterally about the logic 😉 Channelling our inner @takashi who had excellent tips of transforming non-spatial coordinates into spatial coordinates to find complex intersections using spatial intersection transformers, we can conceptualise the data is actually Linestrings.
Eg. “03.02.06.03.02.01” is actually a line with 6 vertices where:
X = Substring Position Number
Y = Substring Numerical Value
Becomes:
LINESTRING(0 3, 1 2, 2 6, 3 3, 4 2, 5 1)
What we can do then, is transform the substring number sequences into Line Geometries with vertex coordinates corresponding to each Substring “Point”, and then use LineOnLineOverlayer to tell you which “partial lines” overlap, which will be just the part of the total string that contains overlapping substrings, per Row Group.
Sample data, with Row Group Number added with a Counter:
Flowing through to AttributeSplitter, this now gives the Y coordinates of the Line vertices, being the Substring numeric values
Build Line Geometries out of this data that are going to find the coincident line parts with LineOnLineOverlayer
Now post-process and using Tester just select the sub-line that absolutely contains a Substring in the 0 X coordinate position (ie. This is a line that does contain the very first substring value) within the Total String AND make sure the Overlap Count that contains the same Count of Valid Columns. ie. We need to ensure this line overlaps 4 times for 4 valid columns. If it only overlapped 3 times then this was one column that did not have the same starting substring value and there would be no common substring then for that row.
The output of the Tester below will be the longest sequence of “points” that being from the starting substring, and matches across all of the columns
Can see for Row 1 in the original table, the longest matching sequence output in the LineOnLineOverlayer List is “03, 02, 06” . I haven’t shown the extra ListExploder, AttributeCreator to put the leading “0” back onto the number and Aggregator to put them back into concantentated, comma-delimited form.
Tbh I had already implemented my attribute splitter → attribute manager with a bunch of conditions idea before you answered which its good enough for now as things are piling up at work. If I have some time I will revisit this later. For now I will mark this as the best answer.