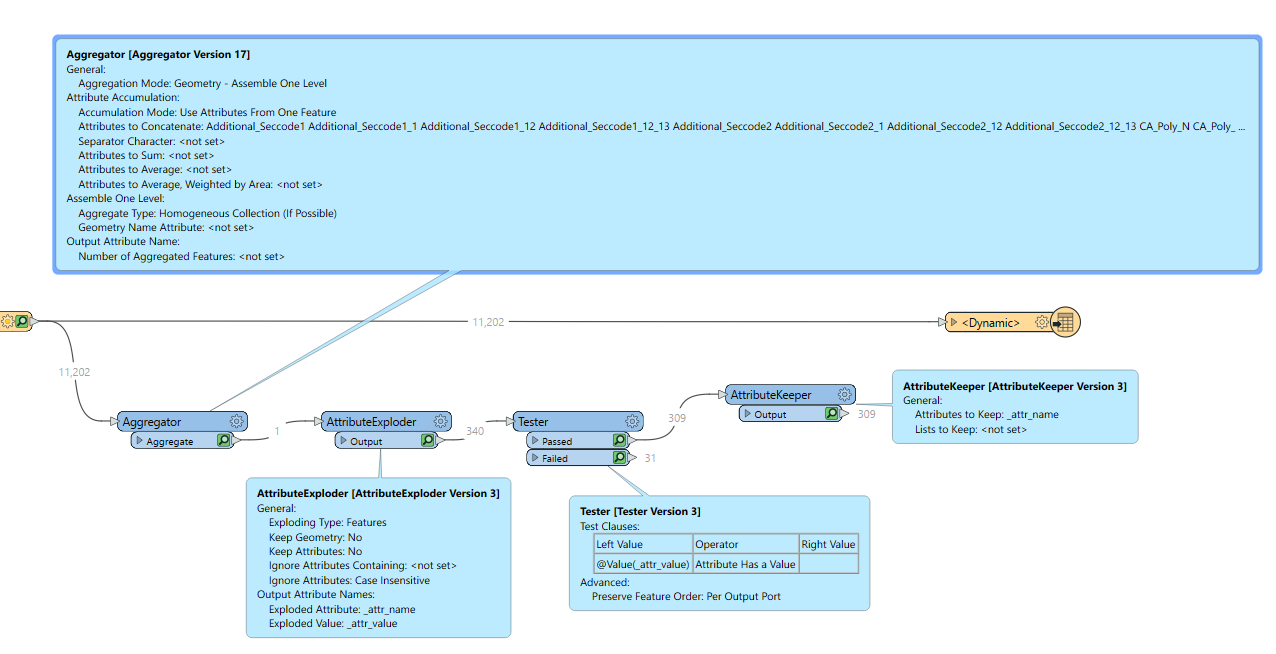
Hi All,
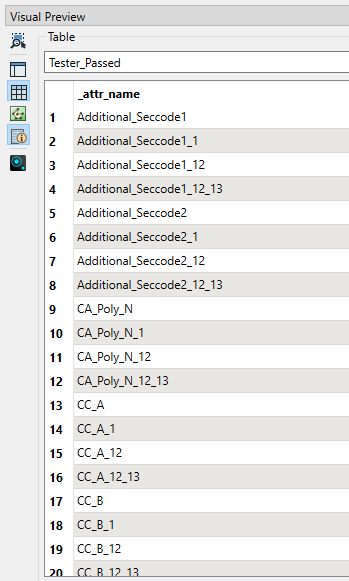
I have a feature class with 351 columns and need to know which columns contains ALL the records as <Null>. I have tried the AttributeValidator transformer but it doesn’t seem to do what I want as all the records go to Failed and there’s definetly columns with all records as <Null>, see below:
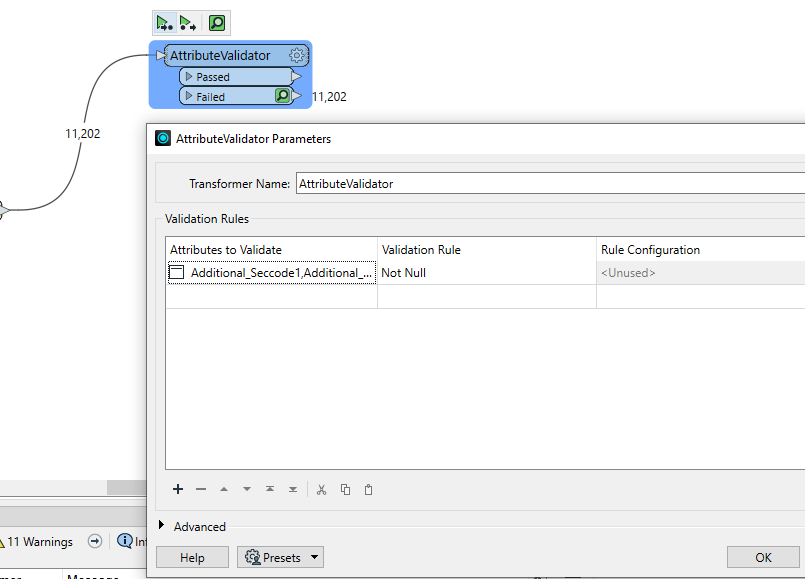
The ‘Attributes to Validate’ have been included the 351 columns,
Any ideas how to approach this issue?
Thanks :)