
I have used @PadLeft(@Format(%.3f,@Value(FLOW)), 8) in an earlier attribute manager in the workspace to format the values to three decimal places and pad left. My output data and workspace are as shown below: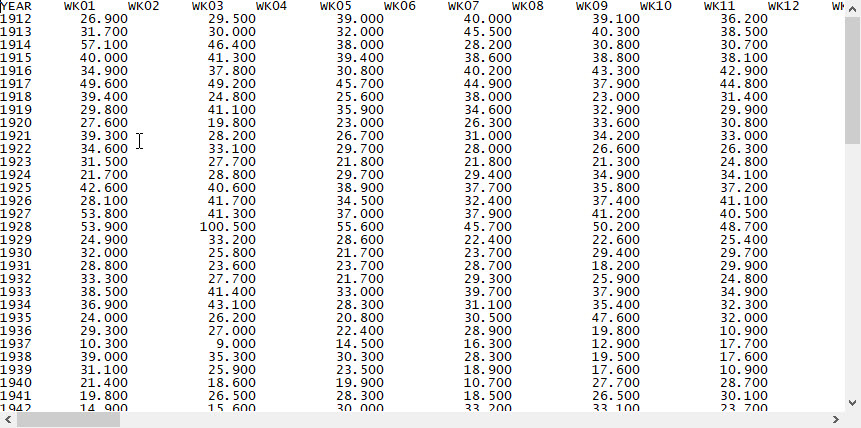

Question
I am writing some tabular data to a text file using the CSV writer. How do I get my attribute names or column headings to align with my attribute values in a right justified manner or padding left?
 +4
+4- Contributor



Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.