Hello,
I am trying to extract html tags from an attribute, however the documentation is very unclear and need further guidance.Page: https://docs.safe.com/fme/html/FME-Form-Documentation/FME-Transformers/Transformers/htmlextractor.htm
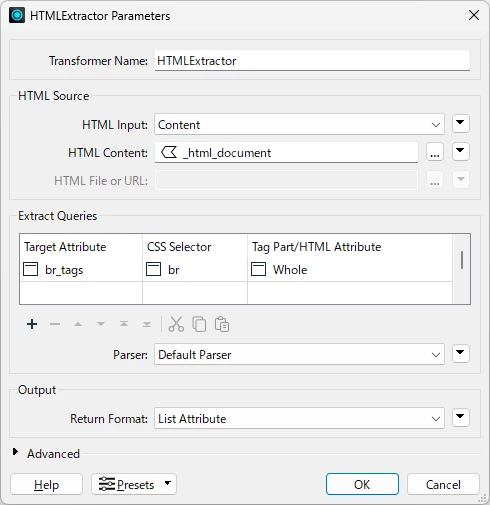
States: “In the HTMLExtractor, a query is constructed to find the div tag with the id “article” (CSS Selector = #article). The contents of that tag will be extracted (Tag Part/HTML Attribute = Value), and output to the new attribute articleText.”
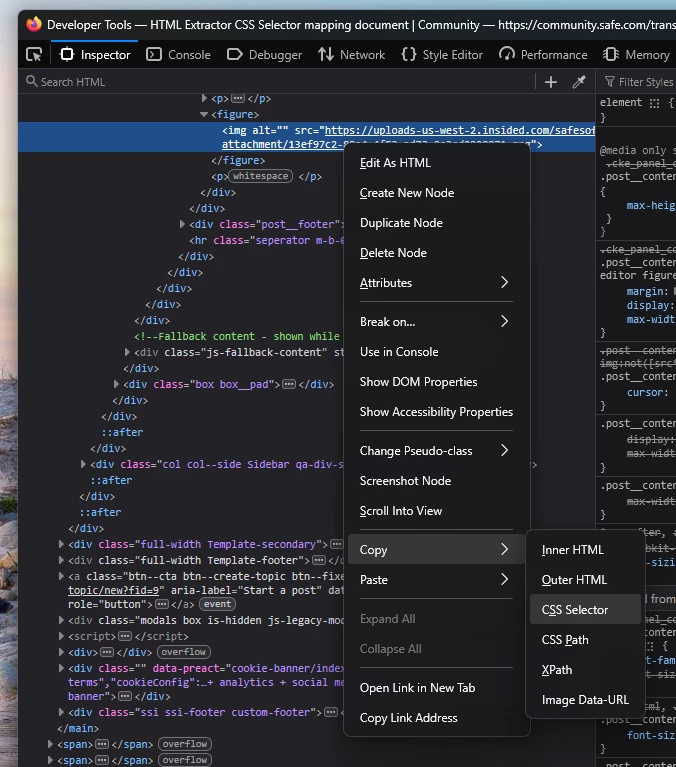
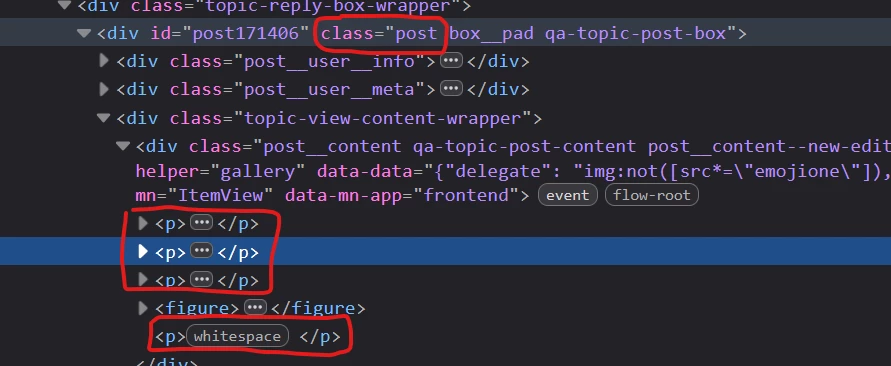
Where is the mapping document that maps FME CSS selector ‘ids’ to html tags? I am trying to extract <br>, what should the CSS selector for this be? Using “br” as the selector and then using a list exploder produces an attribute with empty fields.